{kind=link}

오늘 메타가 소개되었습니다 V-Jepa 2로봇 시스템의 이해, 예측 및 계획을 지원하기 위해 주로 비디오에 대해 훈련 된 12 억 개의 파라미터 세계 모델. JEPA (Joint Embedding Predictive Architecture)를 기반으로하는이 모델은 로봇 및 기타 “AI 에이전트”가 제한된 도메인 별 교육을 통해 익숙하지 않은 환경 및 작업을 탐색하도록 도와 주도록 설계되었습니다.
V-Jepa 2는 추가 인간 주석없이 2 단계 훈련 과정을 따릅니다. 첫 번째 자체 감독 단계 에서이 모델은 백만 시간 이상의 비디오와 1 백만 개의 이미지에서 배우고 물리적 상호 작용 패턴을 캡처합니다. 두 번째 단계는 작은 로봇 제어 데이터 세트 (약 62 시간)를 사용하여 액션 조건 학습을 소개하여 결과를 예측할 때 모델이 에이전트 작업을 고려할 수 있습니다. 이로 인해 모델을 계획 및 폐쇄 루프 제어 작업에 사용할 수 있습니다.
메타는 이미이 새로운 모델을 실험실에서 테스트했다고 밝혔다. Meta는 V-Jepa 2가 비전 기반 목표 표현을 사용하여 픽 앤 플레이스와 같은 일반적인 로봇 작업에서 잘 수행한다고보고합니다. Pick and Place와 같은 간단한 작업의 경우 시스템은 후보 조치를 생성하고 예측 된 결과를 기반으로 평가합니다. v-jepa2는 객체를 집어 들고 올바른 지점에 배치하는 것과 같은 더 강력한 작업을 위해 일련의 시각적 하위 골목을 사용하여 동작을 안내합니다.
내부 테스트에서 Meta는이 모델이 새로운 객체 및 설정으로 일반화 할 수있는 유망한 능력을 보여 주었으며, 성공률은 이전에 보이지 않는 환경에서 픽 앤 플레이스 작업에서 65%에서 80% 사이입니다.
Meta의 AI 과학자 Yann Lecun은“세계 모델은 로봇 공학의 새로운 시대를 안내하여 실제 AI 요원이 천문학적 양의 로봇 훈련 데이터가 필요하지 않고 집안일과 물리적 작업을 도울 수있게 해줄 것이라고 믿는다.
V-Jepa 2는 이전 모델에 비해 개선을 보여 주지만 Meta AI는 이러한 벤치 마크에서 모델과 인간 성능 사이에 눈에 띄는 차이가 남아 있다고 말했다. Meta는 오디오 또는 촉각 정보를 통합하는 등 여러 시간 척도 및 양식에 걸쳐 작동 할 수있는 모델의 필요성을 지적합니다.
비디오에서 물리적 이해의 진보를 평가하기 위해 Meta는 다음 세 가지 벤치 마크를 출시하고 있습니다.
- intphys 2 : 신체적으로 그럴듯한 시나리오를 구별하는 모델의 능력을 평가합니다.
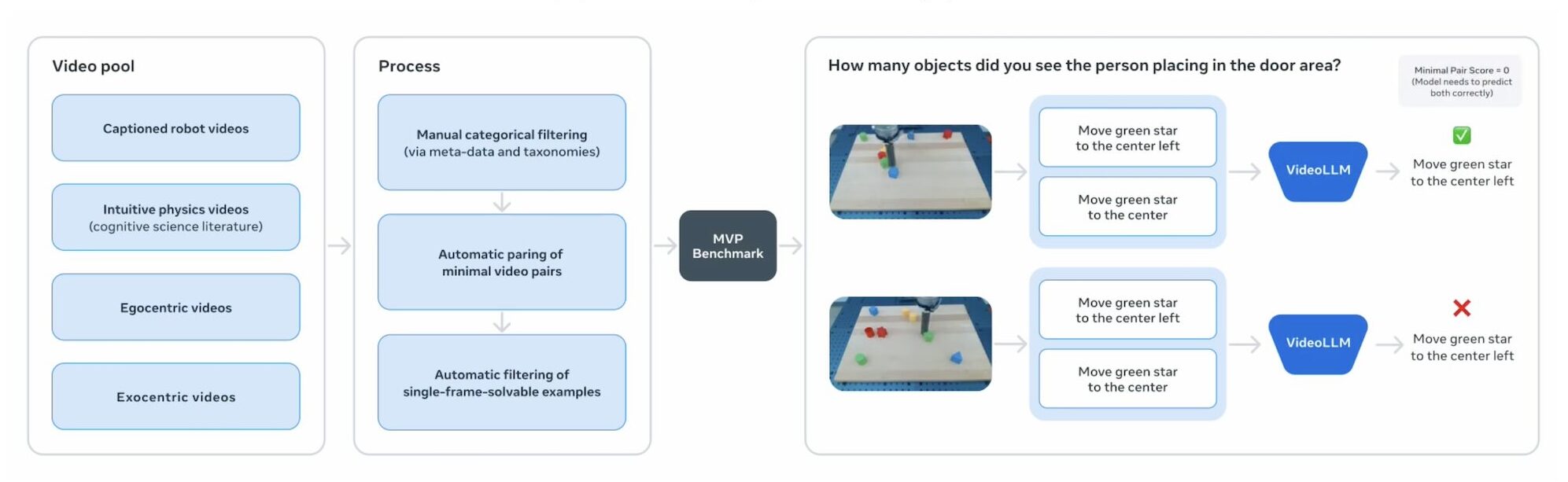
- MVPBENCH : 모델이 비디오 질문 응답에서 데이터 세트 바로 가기보다는 진정한 이해에 의존하는지 여부를 테스트합니다.
- 인과 vqa : 원인과 결과, 기대 및 반 인용에 대한 추론을 조사합니다.
V-Jepa 2 코드 및 모델 체크 포인트는 상업용 및 연구 용도를 위해 사용할 수 있으며, 메타는 로봇 공학 및 구체화 된 AI에서 세계 모델에 대한 광범위한 탐색을 장려하는 것을 목표로합니다.
메타는 자신의 세계 모델을 개발할 때 다른 기술 리더와 합류합니다. Google Deepmind 전체 3D 환경을 시뮬레이션 할 수있는 자체 버전 인 Genie를 개발해 왔습니다. Fei-Fei Li가 설립 한 스타트 업인 World Labs는 대규모 세계 모델을 구축하기 위해 2 억 2 천만 달러를 모금했습니다.
게시물 Meta V-Jepa 2 World Model은 Raw Video를 사용하여 로봇을 훈련시킵니다. 먼저 나타났습니다 로봇 보고서.