{kind=link}

Liquid AI는 기초 모델을 사용하면 특정 작업 및 하드웨어 요구 사항에 대한 품질, 대기 시간 및 메모리 간의 최적의 균형을 달성하기를 희망한다고 말했다. | 출처 : 액체 AI
이번 주 액체 AI는 LFM (Liquid Foundation Model) 인 LFM2를 출시했으며 회사는 품질, 속도 및 메모리 효율 배포의 새로운 표준을 설정한다고 밝혔다.
대형 생성 모델을 먼 구름에서 린으로, 기기로 이동합니다. 이 기능은 전화, 노트북, 자동차, 로봇, 웨어러블, 위성 및 실시간으로 추론 해야하는 기타 엔드 포인트에 필수적인 기능입니다.
Liquid AI는 업계 전반에 걸쳐 빠른 기기 Gen-AI 경험을 제공하도록 모델을 설계하여 생성을위한 수많은 장치를 잠금 해제합니다. 일체 포함 워크로드. 새로운 하이브리드 아키텍처를 기반으로 LFM2는 CPU의 QWEN3보다 두 배 빠른 디코딩 및 프리 필드 성능을 제공합니다. 또한 각 크기 클래스에서 모델을 크게 능가하여 효율적인 AI 에이전트에 전원을 공급하는 데 이상적이라고 회사는 말했다.
매사추세츠 케임브리지 회사 이러한 성능 이득으로 인해 LFM2는 로컬 및 에지 사용 사례에 이상적인 선택이됩니다. 배포 혜택 외에도 새로운 아키텍처 및 교육 인프라는 이전 LFM 생성에 비해 교육 효율성이 3 배 향상되었습니다.
액체 AI 공동 창립자이자 MIT의 컴퓨터 과학 및 인공 지능 연구소 (CSAIL) Daniela Rus의 이사는 로봇 공학 Summit & Expo 2025로봇 보고서에서 제작 한 로봇 개발 이벤트.
LFM2 모델은 오늘 포옹 얼굴에서 사용할 수 있습니다. Liquid AI는 Apache 2.0을 기반으로하는 공개 라이센스에 따라이를 공개합니다. 라이센스를 통해 사용자는 학업 및 연구 목적으로 LFM2 모델을 자유롭게 사용할 수 있습니다. 기업은 또한 더 작은 경우 (수익을 1,000 만 달러 미만) 상업적으로 사용할 수 있습니다.
Liquid AI는 모든 장치를 AI 장치로 로컬로 전환하는 안전한 엔터프라이즈 등급 배포 스택을 갖춘 소규모 멀티 모드 파운데이션 모델을 제공합니다. 이는 Cloud LLM에서 비용 효율적, 빠르고 개인 및 현장 인텔리전스에 이르기까지 Enterprises Pivot으로 인해 시장에서 규모가 큰 점유율을 얻을 수있는 기회를 제공합니다.
LFM2는 무엇을 할 수 있습니까?
액체 AI가 말했다 LFM2 이전 세대에 비해 3 배 빠른 훈련을 달성합니다. 또한 QWEN3에 비해 CPU의 디코딩 및 프리 필 속도까지 최대 2 배 더 빠른 혜택을받습니다. 또한이 회사는 LFM2가 지식, 수학, 지시 다음 및 다국어 기능을 포함한 여러 벤치 마크 범주에서 유사한 크기의 모델보다 성능이 뛰어 났다고 주장했습니다.
LFM2에는 새로운 아키텍처가 장착되어 있습니다. 곱셈 게이트와 짧은 컨볼 루션이있는 하이브리드 액체 모델입니다. 16 개의 블록으로 구성됩니다 : 10 개의 이중 게이트 단거리 컨볼 루션 블록과 그룹화 된 쿼리주의 6 블록.
스마트 폰, 랩톱 또는 차량에 배포 되든 LFM2는 CPU, GPU 및 NPU 하드웨어에서 효율적으로 실행됩니다. 회사의 풀 스택 시스템에는 프로토 타입에서 제품으로의 경로를 가속화하기위한 아키텍처, 최적화 및 배포 엔진이 포함되어 있습니다.
액체 AI는 0.35b, 0.7b 및 1.2b 매개 변수로 3 개의 조밀 한 체크 포인트의 가중치를 방출합니다. 사용자는 지금 액체 놀이터, 포옹 얼굴 및 오픈 러터에서 시도해 볼 수 있습니다.
LFM2는 다른 모델에 대해 어떻게 수행합니까?
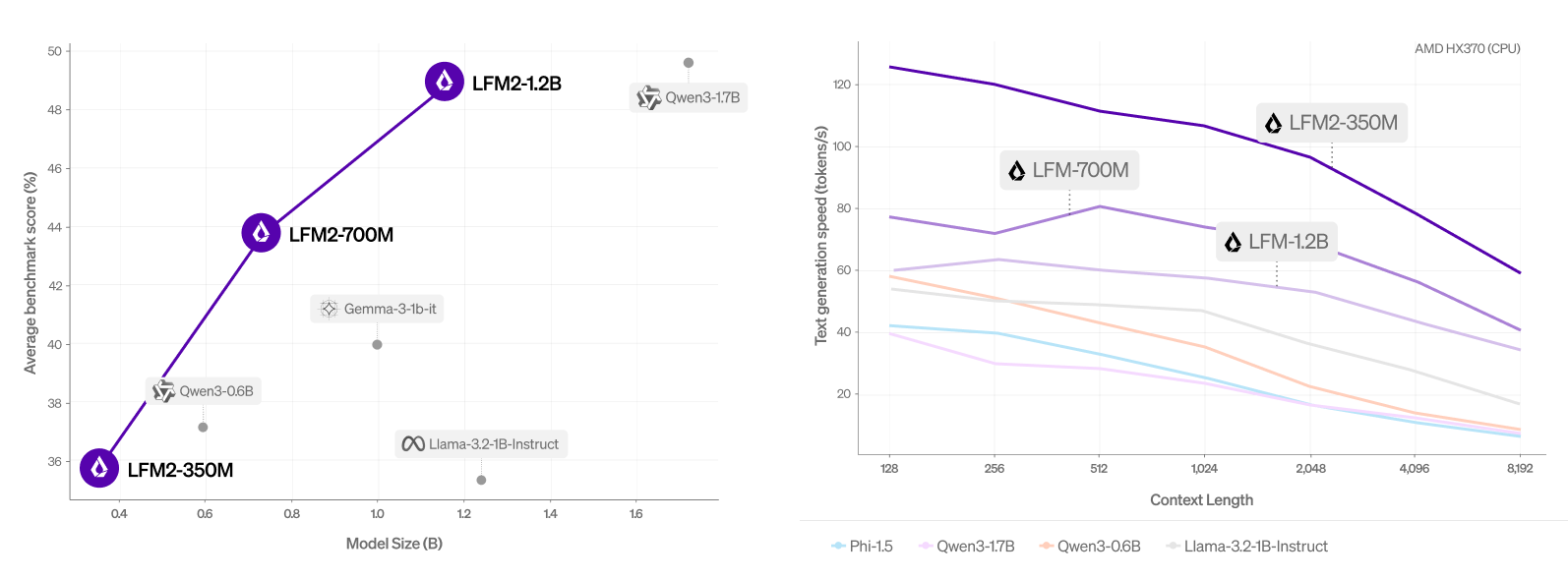
평균 점수 (MMLU, IFEVAL, IFBENCH, GSM8K, MMMLU) 대 모델 크기. | 출처 : 액체 AI
이 회사는 자동화 된 벤치 마크와 LLM-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-AGUDGE 프레임 워크를 사용하여 LFM2를 평가하여 기능에 대한 포괄적 인 개요를 얻었습니다. 이 모델은 다양한 평가 범주에서 유사한 크기의 모델을 능가한다는 것을 발견했습니다.
액체 AI는 또한 지식을 다루는 7 개의 대중 벤치 마크 (5- 샷 MMLU, 0- 샷 GPQA), 지시 다음 (IFEVAL, IFBENCH), 수학 (0- 샷 GSM8K, 5- 샷 MGSM) 및 다국적 MMMLU (5-Shot Openai Mmmlu, 5- 샷 MGSM) (아라비아어, 프렌치, 프렌치, 프렌치, 프렌치, 프렌치, 프렌치, 프렌치, 프렌치, 프렌치, 스페인어 MGSM)에서 LFM2를 평가했습니다. 그리고 중국어).
LFM2-1.2B는 47% 더 큰 매개 변수 수의 모델 인 QWEN3-1.7B와 경쟁적으로 수행한다는 것을 발견했습니다. LFM2-700M은 Gemma 3 1b IT보다 성능이 우수하며, 가장 작은 검문소 LFM2-350M은 QWEN3-0.6B 및 LLAMA 3.2 1B orruct와 경쟁력이 있습니다.
액체 AI 훈련 방법 LFM2
LFM2를 훈련시키고 확장하기 위해이 회사는 낮은 지연이있는 기기 언어 모델 워크로드를 대상으로 3 개의 모델 크기 (350m, 700m 및 1.2b 매개 변수)를 선택했습니다. 모든 모델은 약 75%의 영어, 20% 다국어 및 웹 및 라이센스 자료에서 공급 된 5% 코드 데이터를 포함하는 사전 훈련 코퍼스에서 도출 된 10T 토큰으로 교육을 받았습니다.
LFM2의 다국어 기능을 위해이 회사는 주로 일본어, 아랍어, 한국, 스페인어, 프랑스어 및 독일어에 중점을 두었습니다.
사전 훈련 중에 액체 AI는 기존 LFM1-7B를 지식 증류 프레임 워크에서 교사 모델로 활용했습니다. 이 회사는 LFM2의 학생 출력과 LFM1-7B 교사 출력 사이의 교차 엔트로피를 전체 10T 토큰 교육 프로세스에서 1 차 교육 신호로 사용했습니다. 사전 여지가 32k로 컨텍스트 길이가 연장되었습니다.
교육 후 훈련은 일반적인 능력을 잠금 해제하기 위해 다양한 데이터 혼합물에서 매우 대규모 감독 된 미세 조정 (SFT) 단계로 시작했습니다. 이 소규모 모델의 경우, 회사는 Rag 또는 기능 호출과 같은 대표적인 다운 스트림 작업 세트를 직접 훈련시키는 것이 유리하다는 것을 알게되었습니다. 이 데이터 세트는 오픈 소스, 라이센스 및 대상 합성 데이터로 구성되어 있으며, 여기서 회사는 정량적 샘플 스코어링과 질적 휴리스틱의 조합을 통해 고품질을 보장합니다.
Liquid AI는 오프라인 데이터와 반 온라인 데이터의 조합에서 길이 정규화와 함께 사용자 정의 직접 환경 설정 최적화 알고리즘을 추가로 적용합니다. Semi-Nonline 데이터 세트는 시드 SFT 데이터 세트를 기반으로 모델에서 여러 완료를 샘플링하여 생성됩니다.
그런 다음 회사는 LLM 심사 위원과의 모든 응답을 기록하고 SFT와 정책 샘플 중에서 가장 높고 가장 낮은 점수의 완료를 결합하여 선호도 쌍을 만듭니다. 오프라인 및 반 온라인 데이터 세트는 모두 점수 임계 값에 따라 추가 필터링됩니다. 액체 AI는 초 파라미터 및 데이터 세트 혼합물을 변경하여 여러 후보 검문소를 생성합니다. 마지막으로, 다양한 모델 병합 기술을 통해 최고의 체크 포인트를 최종 모델로 결합합니다.
게시물 액체 AI는 기기 기초 모델 LFM2를 방출합니다 먼저 나타났습니다 로봇 보고서.