

자전거 로터 설치와 같은 장거리 행동을 수행하기 위해 Finetuned LBM의 자율 평가 롤아웃을 사용하는 2 개의 코봇. | 출처 : Toyota Research Institute
이번 주 Toyota Research Institute (TRI)는 이번 주에 일반적인 목적 로봇을 훈련시키는 데 사용할 수있는 LBMS (Large Behavior Model)에 대한 연구 결과를 발표했습니다. 이 연구는 단일 LBM이 수백 가지의 작업을 배우고 사전 지식을 사용하여 80% 적은 교육 데이터로 새로운 기술을 습득 할 수 있음을 보여주었습니다.
LBM은 크고 다양한 조작 데이터 세트에서 사전에 사전입니다. 인기가 높아지고 있음에도 불구하고 로봇 공동체는 LBM이 실제로 제공하는 뉘앙스에 대해 놀랍게도 거의 알지 못합니다. 트리 작업은이 연구를 통해 알고리즘 및 데이터 세트 설계의 최근 진행 상황을 밝히는 것을 목표로합니다.
TRI는 그 결과가 최근 LBM 스타일 로봇 파운데이션 모델의 인기 급증을 지원하며, 다양한 로봇 데이터에 대한 대규모 전제 조치가 더 유능한 로봇을 향한 실용적인 경로라는 증거를 덧붙였다.
범용 로봇은 가정용 로봇이 일상적인 지원을 제공 할 수있는 미래를 약속합니다. 그러나 우리는 모든 로봇이 평균 가계 작업을 해결할 수있는 시점에 없습니다. 로봇 센서 데이터 및 출력 동작을 취하는 LBM 또는 구체화 된 AI 시스템은이를 변경할 수 있다고 TRI는 말했다.
2024 년에 트리가 승리했습니다 RBR50 Robotics Innovation Award 빠른 로봇 교육을위한 작업 구축 LBM.
Tri의 발견에 대한 개요
TRI는 거의 1,700 시간의 로봇 데이터로 일련의 확산 기반 LBM을 교육했으며 1,800 개의 실제 평가 롤아웃과 47,000 개가 넘는 시뮬레이션 롤아웃을 수행하여 능력을 엄격하게 연구했습니다. LBMS를 발견했습니다.
- 스크래치에서 정책에 비해 일관된 성능 향상을 제공합니다
- 다양한 환경 요인에 대한 견고성이 필요한 도전적인 설정에서 3-5 × 적은 데이터로 새로운 작업을 배울 수 있습니다.
- 사전 여파 데이터가 증가함에 따라 꾸준히 향상시킵니다
Tri는 수백 시간의 다양한 데이터와 행동 당 수백 개의 데모만으로 성능이 의미있게 뛰어 내렸다 고 Tri는 말했다. 사전 조정은 예상 스케일보다 일관된 성능 향상을 제공합니다. 인터넷의 로봇 데이터는 아직 없지만 이점은 그 규모보다 훨씬 앞서 나타납니다. 이는 데이터 수집 및 부트 스트랩 성능의 덕이있는주기를 가능하게하는 유망한 신호라고 TRI는 주장했다.
TRI의 평가 제품군에는 몇 가지 새롭고 도전적인 장기 호리존 실제 작업이 포함됩니다. 이 환경에서 Finetuned 및 평가 된 LBM 사전 여지가 이러한 행동이 사전 복제 작업과 매우 다르지만 성능을 향상시킵니다.
TRI의 LBMS 아키텍처 및 데이터 내부
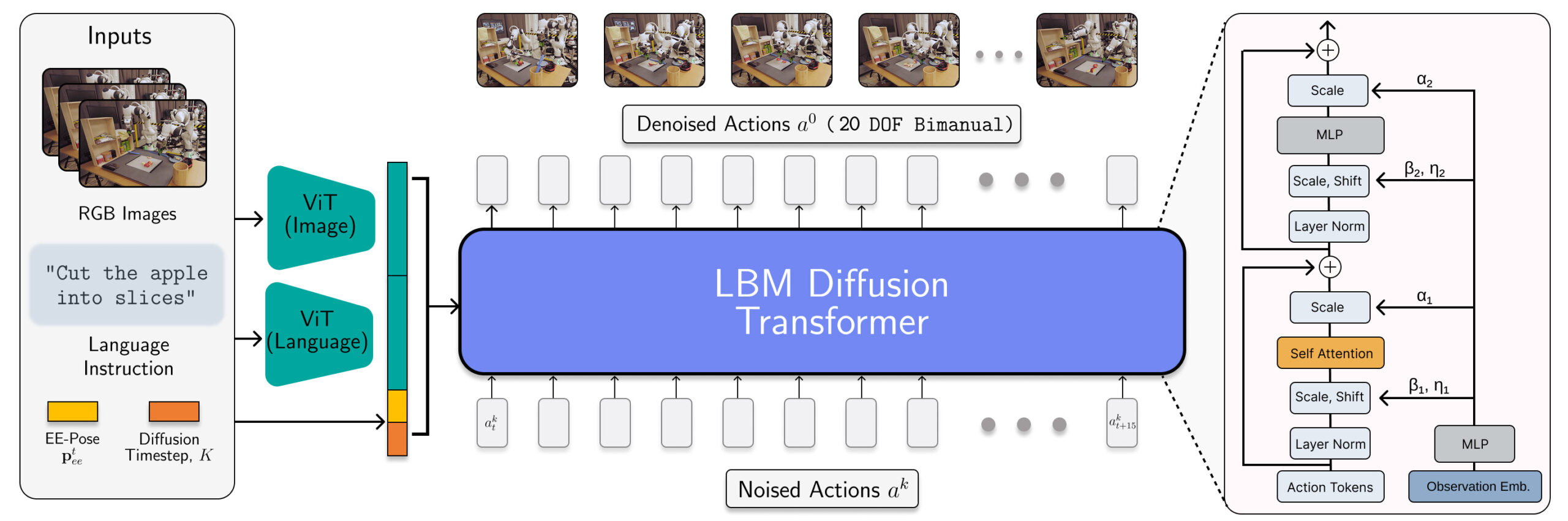
LBM 아키텍처는 로봇 동작을 예측하는 확산 변압기로 인스턴스화됩니다. | 출처 : Toyota Research Institute
TRI의 LBMS는 멀티 모달 VIT 시력-언어 인코더와 ADALN을 통한 인코딩 된 관측치에서 조절 된 변압기 데노이징 헤드를 갖춘 스케일링 멀티 태스킹 확산 정책입니다. 이 모델은 손목과 장면 카메라, 로봇 독점 및 언어 프롬프트를 소비하고 16 개의 타임 스텝 (1.6 초) 액션 청크를 예측합니다.
연구원들은 468 시간의 내부 수집 된 양수 로봇 원격 수술 데이터, 45 시간의 시뮬레이션 수집 된 원격화 데이터, 32 시간의 UMI (Universal Manipulation Interface) 데이터, 개방형 X-embodiment 데이터 세트에서 대략 1,150 시간의 인터넷 데이터를 큐 레이트로 혼합하여 LBMS를 훈련시켰다.
시뮬레이션 데이터의 비율은 적지 만 TRI의 사전 연합 혼합물에 포함되면 SIM과 Real 모두에서 동일한 LBM 체크 포인트를 평가할 수 있습니다.
TRI의 평가 방법
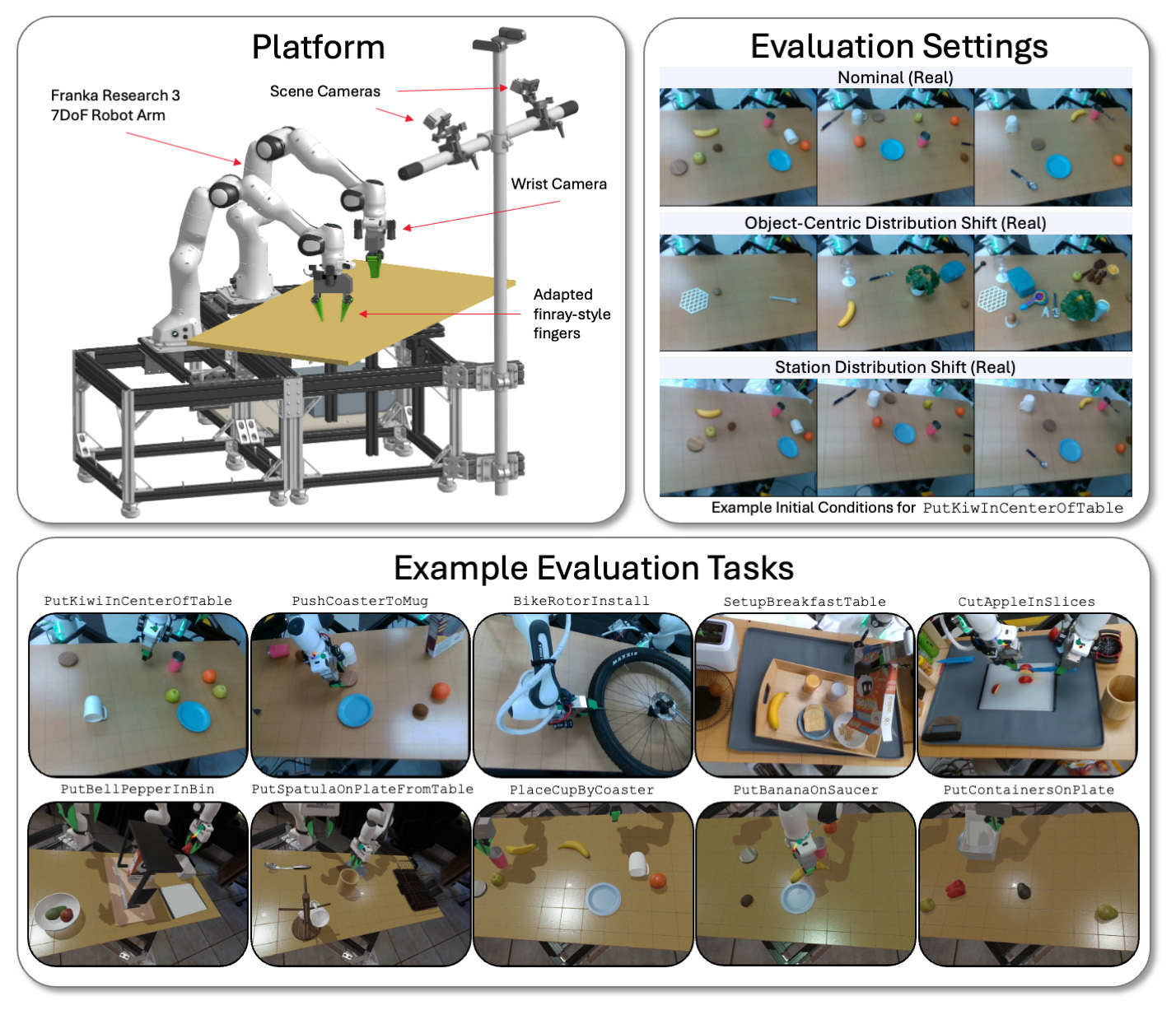
TRI는 시뮬레이션과 실제 세계 모두에서 다양한 작업 및 환경 조건에서 이중 플랫폼에서 LBM 모델을 평가합니다. | 출처 : Toyota Research Institute
TRI는 Franka Panda FR3 암과 최대 6 개의 카메라를 사용하는 물리적 및 드레이크 시뮬레이션 바이먼 스테이션에서 LBM을 평가합니다. 각 손목에 최대 2 개, 정적 장면 카메라 2 개입니다.
보이지 않는 작업 (사전 배치 데이터에 존재 함)과 보이지 않는 작업 (TRI가 전세 된 모델을 미세 조정하는 데 사용하는 것)의 모델을 평가합니다. TRI의 평가 제품군은 16 개의 시뮬레이션 된 Seen-Dering-Praining 과제, 3 개의 실제 시각-징수-예약 작업, 이전에는 보이지 않는 5 개의 장기적인 시뮬레이션 작업 및 이전에 보이지 않는 장기 Horizon Real World 작업으로 구성됩니다.
각 모델은 각 실제 작업에 대해 50 개의 롤아웃과 각 시뮬레이션 작업에 대해 200 개의 롤아웃을 통해 테스트되었습니다. 이를 통해 분석에서 높은 수준의 통계적 엄격함을 얻을 수 있으며, 29 개의 작업에 걸쳐 4,200 개의 롤아웃에 대해 사전 처리 된 모델이 평가되었습니다.
TRI는 실제 세계와 시뮬레이션에서 일관되도록 초기 조건을 신중하게 제어한다고 말했다. 또한 순차적 가설 테스트 프레임 워크를 통해 계산 된 통계적 유의성으로 실제 세계에서 블라인드 A/B 스타일 테스트를 수행합니다.
연구자들이 관찰 한 많은 효과는 경험적 로봇 공학의 비표준 인 표준보다 큰 표본 크기와 신중한 통계 테스트로만 측정 할 수있었습니다. 실험적 변동으로 인한 노이즈는 측정되는 효과를 왜소하게하고, 많은 로봇 공학 용지는 통계 전력이 충분하지 않아 통계적 노이즈를 측정하고있을 수 있습니다.
 초기 새 할인으로 지금 저장하십시오
초기 새 할인으로 지금 저장하십시오{kind=link}
Tri의 연구에서 트라이의 최고의 테이크 아웃
팀의 메인 중 하나 테이크 아웃 사전 해독 데이터가 증가함에 따라 미세한 성능이 원활하게 향상된다는 것입니다. 우리가 조사한 데이터 척도에서 TRI는 성능 불연속 또는 날카로운 변곡점의 증거를 보지 못했습니다. 일체 포함 스케일링은 로봇 공학에서 살아 있고 잘 보입니다.
그러나 TRI는 비 결합되지 않은 사전 RBM과 혼합 된 결과를 경험했습니다. 고무적으로, 단일 네트워크는 많은 작업을 동시에 배울 수 있다는 것을 발견했지만 미세 조정없이 스크래치 단일 작업 교육에서 일관된 성능을 관찰하지는 않습니다. Tri는 이것이 모델의 언어 조향성 때문이라고 기대합니다.
내부 테스트에서 TRI는 더 큰 VLA 프로토 타입이 이러한 어려움을 극복한다는 유망한 초기 징후를 보았지만,이 효과를 고중도 용량 모델에서 엄격하게 조사하기 위해 더 많은 작업이 필요하다고 말했다.
주의 사항에 관해서는, TRI는 데이터 정규화와 같은 미묘한 설계 선택이 성능에 큰 영향을 미칠 수 있으며, 종종 아키텍처 또는 알고리즘 변화를 지배 할 수 있다고 말했다. 성능 변경의 원인을 충족시키지 않도록 이러한 설계 선택이 신중하게 분리되는 것이 중요합니다.
게시물 TRI : 사전 배치 된 대형 행동 모델은 로봇 학습을 가속화합니다 먼저 나타났습니다 로봇 보고서.