{kind=link}


Shengshu의 Vidar 구체화 된 AI 모델은 신체 훈련 데이터 대신 시뮬레이션 된 세계를 사용합니다. 출처 : Adobe Stock, Ice의 Vectorhub
Shengshu Technology Co.는 어제 멀티 뷰 물리 AI 교육 모델 인 Vidar를 출시했습니다. 이는“행동 추론을위한 비디오 확산”을 나타냅니다. 시맨틱 및 비디오 이해에서 Vidu의 기능을 사용하여 Vidar는 제한된 물리적 데이터 세트를 사용하여 실제 환경에서 로봇의 의사 결정을 시뮬레이션한다고 회사는 말했다.
Shengshu Technology는“Vidar는 구체화 된 AI 모델에 대한 교육에 근본적으로 다른 접근법을 제공합니다. “Tesla가 비전 기반 훈련에 중점을두고 Waymo가 Lidar에 의존하는 것처럼 업계는 물리적 AI에 대한 다양한 경로를 탐색하고 있습니다.”
2023 년 3 월에 설립 된 Shengshu Technology는 LLMS (Multimodal Lange Language Models) 개발을 전문으로합니다. 베이징에 본사를 둔이 회사는 MAAS (Mobility-as-A-Service) 및 SaaS (Software-as-A-Service) 제품을 더 똑똑하고 빠르며 확장 가능한 컨텐츠 제작을 제공한다고 밝혔다.
플래그십 비디오 생성 플랫폼으로 보다Shengshu는 대화 형 엔터테인먼트, 광고, 영화, 애니메이션, 문화 관광 등을 포함한 분야에 걸쳐 전 세계 200 개 이상의 국가 및 지역에서 사용자에게 도달했다고 밝혔다.
Vidar는 로봇 개발을 가속화하기위한 교육을 시뮬레이션했습니다
“일부 회사는 물리적 인 훈련을합니다 일체 포함 Shengshu 기술은“실제 로봇에 모델을 포함시키고 로봇이 겪는 물리적 상호 작용을 통해 데이터를 수집함으로써 비용이 많이 들고 하드웨어 의존적이며 확장하기 어려운 방법입니다.”라고 Shengshu 기술은 말했습니다.“다른 사람들은 순전히 시뮬레이션 된 교육에 의존하지만 종종 실제 배치에 필요한 다양성과 에지 케이스 데이터가 부족합니다.
Vidar는 다른 접근 방식을 취한다고 회사는 주장했다. 제한된 신체 훈련 데이터와 생성 비디오를 결합하여 예측을하고 새로운 가상 시나리오를 생성하여 멀티 뷰를 만듭니다. 시뮬레이션 가상 공간 내에서 생명과 같은 훈련 환경을 특징으로합니다. Shengshu는이를 통해 물리 세계 데이터 수집의 시간, 비용 또는 한계없이보다 강력하고 확장 가능한 교육을 제공 할 수 있다고 Shengshu는 설명했다.
Vidu 생성 비디오 모델 위에 구축 된 Vidar는 멀티 뷰 비디오 예측으로 듀얼 암 조작 작업을 수행 할 수 있으며 미세 조정 후 자연적인 음성 명령에 응답 할 수 있습니다. 모델 이 회사는 효과적으로 실제 행동을위한 디지털 두뇌 역할을하고 있다고 말했다.
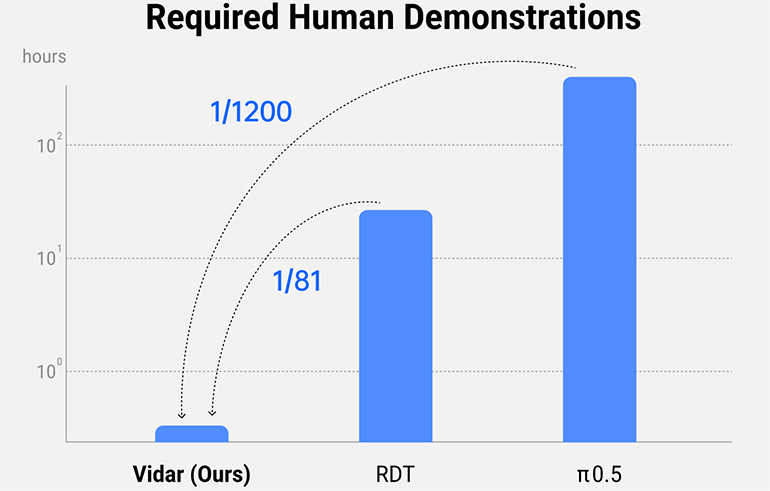
Vidu는 Vidu의 생성 비디오 엔진을 사용하여 대규모 시뮬레이션을 생성하여 실제 데이터에 대한 의존성을 줄이고 실제 AI 에이전트를 훈련시키는 데 필요한 복잡성과 풍부함을 유지합니다. Shengshu는 Vidar는 20 분의 훈련 데이터에서 일반화 된 일련의 로봇 행동 및 작업을 외삽 할 수 있다고 말했다. 이 회사는 RDT 및 π0.5를 포함한 업계 최고의 모델을 훈련시키는 데 필요한 데이터의 1/80에서 1/1,200 사이라고 주장했다.
Shengshu는 Vidar의 핵심 혁신은 모듈 식 2 단계 학습 아키텍처에 있다고 말했다. 인식과 제어를 병합하는 전통적인 방법과 달리 Vidar는 유연성과 확장 성을 높이기 위해 두 개의 별개의 단계로 분해됩니다.
상류 단계에서, 대규모 일반 비디오 데이터와 중간 규모의 구체화 된 비디오 데이터는 지각 적 이해를 위해 Vidu의 모델을 훈련시키는 데 사용됩니다.
두 번째 다운 스트림 단계에서는 Anypos라는 작업 공연 모델이 그 시각적 이해를 로봇의 실행 가능한 모터 명령으로 바꿉니다. 이 분리는 다양한 유형의 로봇에 걸쳐 AI를 훈련하고 배치하는 동시에 비용을 낮추고 확장 성을 높이기가 훨씬 쉽고 빠릅니다.
Vidar는 AI 모델을 훈련시키는 데 필요한 교육 데이터의 양을 줄이기 위해 설계되었습니다. 출처 : Shengshu 기술.
Vidar 확장 가능한 구체화 된 지능을위한 프레임 워크
Vidar는 지난 10 년간 AI 혁신의 언어 및 이미지 기초 모델에서 영감을 얻은 확장 가능한 교육 프레임 워크를 따릅니다. Shengshu는 대규모 제네릭 비디오, 구체화 된 비디오 데이터 및 로봇 별 예제에 걸쳐있는 3 계층 데이터 피라미드가보다 유연한 시스템을 만들어 기존 데이터 병목 현상을 줄였습니다.
광범위한 멀티 모달 생성 작업을위한 확산 모델 및 변압기 아키텍처의 융합을 탐구하는 U-Vit 아키텍처를 기반으로 한 Vidar Harnesses 장기 시간적 모델링 및 다중 색상의 비디오 일관성을 통해 물리적으로 근거가있는 의사 결정을 전제합니다.
이 디자인은 시뮬레이션에서 실제 배포로 빠른 전송을 지원한다고 Shengshu는 동적 환경의 로봇 공학에 중요하다고 말했다. 또한 회사에 따르면 엔지니어링 복잡성을 최소화합니다.
Shengshu는 Vidar가 여러 부문에서 로봇 공학 채택을 촉진 할 수 있다고 말했다. 홈 어시스턴트 및 노인 케어에서 스마트 제조 및 의료 로봇 공학에 이르기 까지이 모델은 새로운 환경과 멀티 태스킹 시나리오에 빠르게 적응할 수 있으며, 모두 최소한의 데이터로 덧붙였다.
Shengshu는 Vidar는 효율적이고 확장 가능하며 비용 효율적인 로봇 공학 개발을위한 AI- 기본 경로를 만듭니다. 이 회사는 일반 비디오를 실행 가능한 로봇 지능으로 변환 함으로써이 모델은 시각적 이해와 구체화 된 기관의 격차를 해소 할 수 있다고 말했다.

Vidar에는 모듈 식 학습 아키텍처가 있습니다. 출처 : Shengshu 기술
Shengshu는 멀티 모달 AI에서 이정표를 표시합니다
Vidar는 Vidu Video Foundation 모델의 빠른 운동량을 기반으로했다고 Shengshu는 말했다. 회사는 데뷔 이후 통계를 나열했습니다.
- Vidu는 한 달 안에 백만 명의 사용자에게 도달했습니다
- 단 3 개월 만에 천만 명의 사용자를 능가했습니다
- 4 월까지 1 억 개가 넘는 비디오를 생성했습니다
- 참조-비디오 생성은 8 월까지 1 억을 초과했습니다
- 총 생성 된 비디오는 이제 3 억 위에 올랐습니다
Shengshu는 멀티 모달 AI의 국경을 계속 확장하고 있으며, Vidar는 다음 국경을 나타내며, 일반화, 생성 및 구체 예를 하나의 통합 시스템으로 브링합니다.
편집자 주 : Robobusiness 캘리포니아 주 산타 클라라에서 10 월 15 일과 16 일에있을 2025 년에는 트랙이 포함됩니다. 물리적 ai 그리고 휴머노이드 로봇. 등록이 시작되었습니다.

게시물 Shengshu Technology는 Vidar 멀티 뷰 물리 AI 교육 모델을 출시합니다 먼저 나타났습니다 로봇 보고서.