{kind=link}


이 기사에서는 ‘Hunyuancustom’이라는 멀티 모달 hunyuan 비디오 월드 모델의 새로운 릴리스에 대해 설명합니다. 새 논문의 폭 넓은 범위는 프로젝트 페이지*, 우리는 평소보다 더 일반적인 범위를 제한 하고이 릴리스와 함께 제공되는 막대한 양의 비디오 자료를 제한된 것으로 제한합니다 (많은 비디오는 레이아웃의 가독성을 향상시키기 위해 상당한 재 편집 및 처리가 필요하기 때문입니다).
이 논문은 API 기반 생성 시스템 Kling을 ‘keling’으로 지칭합니다. 명확성을 위해, 나는 대신 ‘Kling’을 언급합니다.
Tencent는 새로운 버전의 새로운 버전을 공개하는 과정에 있습니다. 후유아 비디오 모델제목 hunyuancustom. 새로운 릴리스는 분명히 만들 수 있습니다 hunyuan lora 모델 사용자가 하나의 영상:
플레이하려면 클릭하십시오. 프롬프트 : ‘남자는 부엌에서 음악을 듣고 달팽이 국수를 요리하고 있습니다.’ 새로운 방법은 Kling을 포함한 근접 소스 및 오픈 소스 방법과 비교 하여이 공간에서 중요한 상대입니다. 출처 : https://hunyuancustom.github.io/ (경고 : CPU/Memory-Intensive Site!)
위의 비디오의 왼쪽 열에서, 우리는 Hunyuancustom에 제공된 단일 소스 이미지를보고, 두 번째 열에서 프롬프트에 대한 새로운 시스템의 해석을 볼 수 있습니다. 나머지 열은 다양한 독점 및 FOSS 시스템의 결과를 보여줍니다. 클링; 보다; 피카; 빗발; 그리고 핏기 없는-기반을 둔 SkyReles-A2.
아래 비디오에서는이 릴리스에 필수적인 세 가지 시나리오의 렌더링이 있습니다. 사람 + 대상; 단일 특성 에뮬레이션; 그리고 가상 시험 온 (사람 + 옷) :
플레이하려면 클릭하십시오. Hunyuan Video의 지원 사이트의 자료에서 편집 된 세 가지 예.
우리는이 예에서 몇 가지 사항을 알 수 있으며, 주로 시스템과 관련된 시스템과 관련이 있습니다. 단일 소스 이미지, 동일한 주제의 여러 이미지 대신.
첫 번째 클립에서 남자는 본질적으로 카메라를 향하고 있습니다. 그는 머리를 20-25 도의 회전 도하로 내려 가서 옆으로 떨어 뜨 렸지만, 그로 인해 경향이있을 때 시스템은 실제로 프로필에서 어떻게 보이는지 추측해야합니다. 이것은 어렵고 아마도 단독 정면 이미지에서 정확하게 측정하는 것은 불가능합니다.
두 번째 예에서 우리는 어린 소녀가 웃는 그녀가 단일 정적 소스 이미지에있는 것처럼 렌더링 된 비디오에서. 다시 말하지만,이 유일한 이미지가 참조로서, hunyuancustom은 그녀의 ‘휴식 얼굴’의 모습에 대해 비교적 정보가없는 추측을해야합니다. 또한, 그녀의 얼굴은 이전의 예 ( ‘사람을 먹는 사람’)보다 카메라를 향한 자세에서 벗어나지 않습니다.
마지막 예에서, 우리는 소스 자료 (여성과 그녀가 입는 옷이 착용하라는 옷)가 완전한 이미지가 아니기 때문에 렌더가 시나리오를 잘라 냈다는 것을 알 수 있습니다. 이는 실제로 데이터 문제에 대한 좋은 해결책입니다!
요점은 새로운 시스템이 여러 이미지 (예 : 사람 + 칩또는 사람 + 옷), 그것은 분명히 여러 각도 나 대체 뷰를 허용하지 않습니다. 단일 캐릭터의따라서 다양한 표현이나 비정상적인 각도를 수용 할 수 있습니다. 따라서이 시스템은이 시스템이 일어났습니다 hunyuanvideo 주변은 지난 12 월에 출시 된 이후 Hunyuanvideo가 Hunyuanvideo가 모든 각도에서 일관된 문자를 생산하는 데 도움이 될 수 있으며 훈련 데이터 세트에 표현되는 모든 얼굴 표정 (20-60 이미지는 일반적)입니다.
소리를 위해 유선
오디오의 경우 Hunyuancustom이 활용합니다 잠복 시스템 (애호가가 공급하는 오디오 및 텍스트와 일치하는 립 움직임을 얻기 위해 시스템 (취미가 설정 및 좋은 결과를 얻기가 어렵습니다).
오디오 기능. 플레이하려면 클릭하십시오. Hunyuancustom 보충 사이트의 립스 동기의 다양한 예가 함께 편집되었습니다.
글을 쓰는 시점에는 영어 사례가 없지만,이를 제작하는 방법이 쉽게 설치 될 수 있고 접근 할 수있는 경우에는 다소 좋은 것으로 보입니다.
기존 비디오 편집
새로운 시스템은 비디오 간 비디오 (V2V 또는 VID2VID) 편집에 대한 매우 인상적인 결과를 제공하며, 여기서 기존 (실제) 비디오의 세그먼트는 단일 참조 이미지에 제공된 주제로 지능적으로 대체됩니다. 아래는 보충 자료 사이트의 예입니다.
플레이하려면 클릭하십시오. 중심 객체만이 목표로하지만 주변에 남아있는 것은 Hunyuancustom Vid2vid 패스에서도 변경됩니다.
우리가 볼 수 있듯이 VID2VID 시나리오에서 표준으로 전체 비디오 대상 영역 (즉, 봉제 장난감)에서 가장 많이 변경되었지만 프로세스에 의해 어느 정도까지 변경됩니다. 아마도 파이프 라인은 쓰레기 무광택 비디오 컨텐츠의 대부분을 원본과 동일하게 만드는 접근 방식. 이것은 Adobe Firefly가 후드 아래에서하는 일이며 꽤 잘합니다. 그러나 FOSS 생성 장면에서는 연구 과정입니다.
즉, 제공된 대부분의 대체 예는 아래의 조립 된 편집에서 볼 수 있듯이 이러한 통합을 목표로하는 더 나은 작업을 수행합니다.
플레이하려면 클릭하십시오. hunyuancustom에서 vid2vid를 사용하여 interjected 컨텐츠의 다양한 예를 들었으며, 표적화되지 않은 재료에 대해 주목할만한 존중을 나타냅니다.
새로운 시작?
이 이니셔티브는 개발입니다 Hunyan 비디오 프로젝트그 개발 흐름에서 멀리 떨어진 하드 피벗이 아닙니다. 이 프로젝트의 개선 사항은 구조적 변화를 휩쓸지 않고 개별 아키텍처 삽입으로 도입되어 모델이 의존하지 않고 프레임 전체에 걸쳐 정체성 충실도를 유지할 수 있습니다. 주제 별 미세 조정LORA 또는 텍스트 반전 접근법과 마찬가지로.
그러므로 hunyuancustom은 처음부터 훈련되지 않고 2024 년 12 월 Hunyuanvideo Foundation 모델의 미세 조정입니다.
Hunyuanvideo Loras를 개발 한 사람들은 그들이이 새로운 판에서 여전히 일할 것인지 아니면 Lora Wheel을 재창조 해야하는지 궁금해 할 것입니다. 다시 한번 이 새로운 릴리스에 내장 된 것보다 더 많은 사용자 정의 기능을 원한다면.
일반적으로, 저 스케일 모델의 심하게 미세 조정 된 방출은 모델 가중치 이전 모델을 위해 만든 Loras는 새로 정제 된 모델로 제대로 작동하지 않거나 전혀 작동하지 않습니다.
그러나 때로는 미세 조정의 인기가 그 기원에 도전 할 수 있습니다. 미세 조정이 효과적이되는 한 가지 예 포크전용 생태계와 그 자체의 추종자와 함께 조랑말 확산 튜닝 안정적인 확산 XL (SDXL). Pony는 현재 592,000 개 이상의 다운로드를 보유하고 있습니다 끊임없이 변화 Civitai 도메인, 광대 한 Loras가 기본 모델로 조랑말 (SDXL이 아님)을 사용하고 추론 시간에 조랑말이 필요합니다.
출시
그만큼 프로젝트 페이지 for the 새로운 종이 (제목이 있습니다 Hunyuancustom : 맞춤형 비디오 생성을위한 멀티 모달 구동 아키텍처) 기능 링크는 a에 대한 링크입니다 Github 사이트 제가 글을 쓸 때, 단지 기능이되었으며 제안 된 타임 라인 (아직 오는 유일한 중요한 것은 Comfyui 통합입니다)과 함께 로컬 구현에 필요한 모든 코드와 필요한 가중치를 포함하는 것으로 보입니다.
글을 쓰는 시점에서 프로젝트 포옹 얼굴 존재 그러나 여전히 404입니다. 그러나 API 기반 버전 WeChat 스캔 코드를 제공 할 수있는 한, 시스템을 분명히 데모 할 수있는 곳.
나는 hunyuancustom에서 분명한 것처럼 한 조립품에서 그러한 다양한 프로젝트의 정교하고 광범위한 사용법을 거의 보지 못했습니다. 아마도 일부 라이센스 중 일부는 전체 릴리스를 의무화 할 것입니다.
Github 페이지에서 두 가지 모델이 발표됩니다 : 8) GPU 피크 메모리 8) 필요한 720px1280px 버전 및 60GB의 GPU 피크 메모리가 필요한 512px896px 버전.
저장소 상태 ‘필요한 최소 GPU 메모리는 720px1280px129f의 경우 24GB이지만 매우 느립니다… 더 나은 생성 품질을 위해 80GB 메모리가 장착 된 GPU를 사용하는 것이 좋습니다.’ – 시스템이 지금까지 Linux에서만 테스트되었음을 반복합니다.
초기 Hunyuan 비디오 모델은 공식 릴리스 이후 양자화 24GB 미만의 VRAM에서 실행할 수있는 크기까지, 새로운 모델이 커뮤니티에서보다 소비자 친화적 인 형태로 채택 될 것이라고 가정하는 것이 합리적이며 Windows 시스템에서도 빠르게 사용될 것이라고 가정합니다.
이 릴리스와 함께 시간 제약과 압도적 인 정보가 수반되기 때문에이 릴리스를 심도있게 살펴 보는 것이 아니라 더 넓어 질 수 있습니다. 그럼에도 불구하고, hunyuancustom에서 후드를 조금 튀어 올 봅시다.
종이를보세요
Hunyuancustom의 데이터 파이프 라인은 분명히 준수합니다 GDPR 프레임 워크에는 합성 및 오픈 소스 비디오 데이터 세트를 모두 포함합니다 OpenHumanvid8 개의 핵심 범주가 표시됩니다. 인간,,, 동물,,, 식물,,, 풍경,,, 차량,,, 사물,,, 건축학그리고 일본 만화 영화.

릴리스 용지에서 Hunyuancustom Data Construction 파이프 라인의 다양한 기여 패키지에 대한 개요. 출처 : https://arxiv.org/pdf/2505.04512
초기 필터링이 시작됩니다 pyscenedetect이는 비디오를 단일 샷 클립으로 분류합니다. Textbpn-plus-plus 그런 다음 과도한 화면 텍스트, 자막, 워터 마크 또는 로고가 포함 된 비디오를 제거하는 데 사용됩니다.
해상도 및 기간의 불일치를 해결하기 위해 클립의 길이는 5 초로 표준화되고 짧은 쪽의 512 또는 720 픽셀로 크기를 조정합니다. 미적 필터링을 사용하여 처리됩니다 코알라 -36m새로운 논문의 연구원들이 큐 레이션 한 사용자 정의 임계 값이 0.06 인 사용자 정의 데이터 세트에 적용됩니다.
대상 추출 프로세스가 결합됩니다 qwen7b 큰 언어 모델 (LLM), the yolo11x 객체 인식 프레임 워크 및 인기 Insightface 인간 정체성을 식별하고 검증하기위한 건축.
인간이 아닌 대상의 경우 Qwenvl 그리고 샘 2 관련 경계 박스를 추출하는 데 사용됩니다 너무 작다면 폐기됩니다.

Hunyuan Control Project에 사용 된 Grounded Sam 2를 사용한 시맨틱 세분화의 예. 출처 : https://github.com/idea-research/ground-sam-2
다중 개체 추출이 사용됩니다 Florence2 경계 박스 주석 및 세분화를 위해 SAM 2를 접지 한 다음, 훈련 프레임의 클러스터링 및 시간 세분화.
처리 된 클립은 hunyuan 팀이 개발 한 독점적 구조적 표지 시스템을 사용하여 설명 및 카메라 모션 큐와 같은 계층화 된 메타 데이터를 제공하는 주석을 통해 추가로 향상됩니다.
마스크 확대 경계 박스로의 전환을 포함한 전략은 훈련 중에 적용되었습니다. 지나치게 적합합니다 모델이 다양한 객체 모양에 적응해야합니다.
오디오 데이터는 상기 언급 된 잠재력을 사용하여 동기화되었으며 동기화 점수가 최소 임계 값 미만으로 떨어지면 클립이 폐기되었습니다.
블라인드 이미지 품질 평가 프레임 워크 hyperiqa 40 세 미만의 비디오를 제외하는 데 사용되었습니다 (Hyperiqa의 맞춤형 규모). 그런 다음 유효한 오디오 트랙을 처리했습니다 속삭임 다운 스트림 작업에 대한 기능을 추출합니다.
저자가 통합합니다 용암 주석 단계에서 언어 보조 모델이며,이 프레임 워크가 hunyuancustom에서 가지고있는 중심 위치를 강조합니다. LLAVA는 이미지 캡션을 생성하고 텍스트 프롬프트와 시각적 컨텐츠를 정렬하는 데 사용되며, 양식에 걸쳐 일관된 훈련 신호의 구성을 지원합니다.
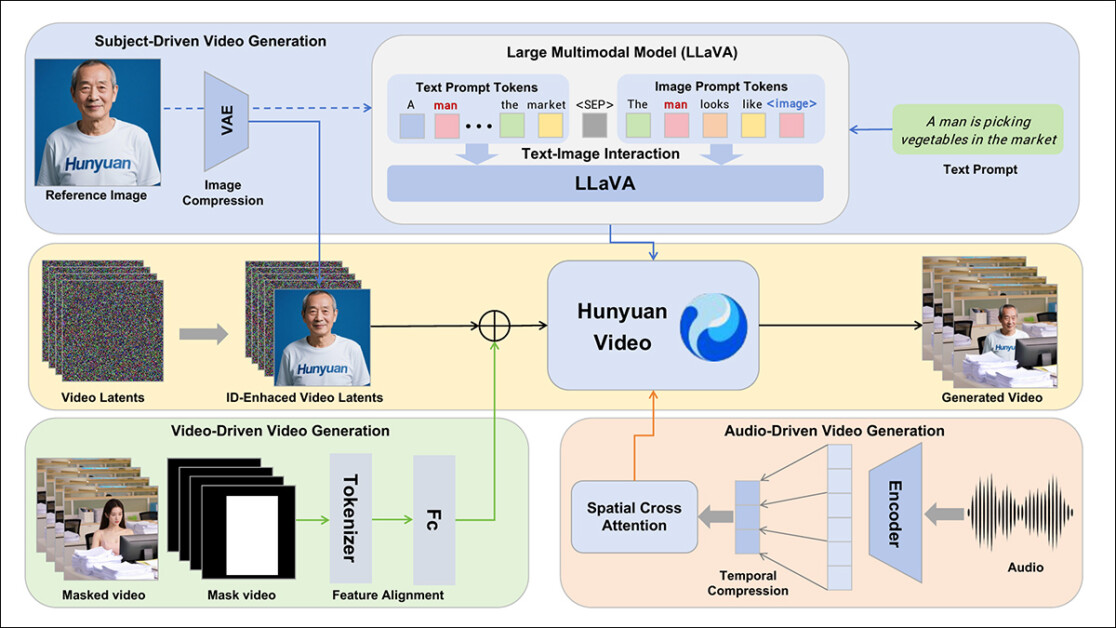
Hunyuancustom Framework는 텍스트, 이미지, 오디오 및 비디오 입력에 조건 된 ID와 일관된 비디오 생성을 지원합니다.
Llava의 비전 언어 정렬 기능을 활용함으로써 파이프 라인은 시각적 요소와 텍스트 설명 사이의 의미 론적 일관성의 추가 계층을 얻습니다.
맞춤형 비디오
참조 이미지와 프롬프트를 기반으로 비디오 생성을 허용하기 위해 Llava를 중심으로 한 두 모듈이 생성되어 먼저 텍스트와 함께 이미지를 수락 할 수 있도록 Hunyuanvideo의 입력 구조를 조정했습니다.
여기에는 이미지를 직접 포함 시키거나 짧은 신원 설명으로 태그를 붙이는 방식으로 프롬프트를 형식화하는 것이 포함되었습니다. 분리기 토큰을 사용하여 이미지 임베드가 프롬프트 내용을 압도하는 것을 막기 위해 사용되었습니다.
Llava의 Visual Encoder는 이미지 및 텍스트 기능 (특히 단일 참조 이미지를 일반적인 의미 론적 임베딩으로 변환 할 때) 동안 세밀한 공간 세부 사항을 압축하거나 버리는 경향이 있으므로 신원 향상 모듈 통합되었습니다. 거의 모든 비디오 잠재 확산 모델은 LORA없이 5 초 클립에서도 정체성을 유지하는 데 어려움이 있기 때문에 커뮤니티 테스트 에서이 모듈의 성능이 중요 할 수 있습니다.
어쨌든, 기준 이미지는 원래 Hunyuanvideo 모델의 인과 3D-VAE를 사용하여 크기를 조정하고 인코딩합니다. 숨어 있는 시간 축을 가로 지르는 비디오에 삽입되었으며, 공간 오프셋이 적용되어 이미지가 출력에서 직접 재생되는 것을 방지하고 여전히 생성을 안내합니다.
이 모델은 사용하여 훈련되었습니다 흐름 일치a 로짓-정상 배포 – 네트워크는이 시끄러운 잠복에서 올바른 비디오를 복구하도록 훈련되었습니다. Llava와 비디오 생성기는 모두 미세 조정되어 이미지와 프롬프트가 출력을보다 유창하게 안내하고 대상 아이덴티티를 일관되게 유지할 수 있습니다.
다중 개체 프롬프트의 경우 각 이미지 텍스트 쌍이 별도로 내장되어 뚜렷한 시간 위치를 할당하여 아이덴티티를 구별하고 관련 장면의 생성을 지원합니다. 다수의 상호 작용하는 과목.
소리와 비전
Hunyuancustom 조건 사용자 입력 오디오와 텍스트 프롬프트를 사용하여 오디오/음성 생성으로 설명 된 설정을 반영하는 장면 내에서 문자가 말할 수 있습니다.
이를 지원하기 위해, 신원 디센트 혈이 적 오디오 모듈은 참조 이미지 및 프롬프트에서 내장 된 ID 신호를 방해하지 않고 오디오 기능을 소개합니다. 이러한 기능은 압축 비디오 타임 라인과 일치하고 프레임 레벨 세그먼트로 나누고 공간을 사용하여 주입됩니다. 상호 관찰 각 프레임을 분리하여 대상 일관성을 보존하고 시간 간섭을 피하는 메커니즘.
두 번째 시간 주입 모듈은 타이밍 및 모션을 더 잘 제어하고, 오디오와 함께 일하고, 오디오 기능을 잠재 시퀀스의 특정 영역에 매핑하고, 사용합니다. 다층 퍼셉트론 (MLP)로 변환합니다 토큰 면적 모션 오프셋. 이를 통해 제스처와 얼굴 움직임은 더 큰 정밀도로 구어 입력의 리듬과 강조를 따를 수 있습니다.
Hunyuancustom을 사용하면 기존 비디오의 피사체를 직접 편집 할 수 있으며, 전체 클립을 처음부터 전체 클립을 재건 할 필요없이 사람이나 객체를 장면으로 교체하거나 삽입 할 수 있습니다. 이렇게하면 외관이나 움직임을 대상으로 변경하는 작업에 유용합니다.
플레이하려면 클릭하십시오. 보충 사이트의 추가 예.
기존 비디오에서 효율적인 주제 교체를 용이하게하기 위해 새로운 시스템은 현재 인기와 같은 최근 방법의 리소스 집약적 접근을 피합니다. vace또는 전체 비디오 시퀀스를 함께 병합하는 것, 사전에 사전 된 인과 관계 3D-VAE를 사용하여 참조 비디오의 압축을 선호합니다-Generation Pipeline의 내부 비디오 잠복과 정렬 한 다음 두 사람을 함께 추가합니다. 이는 프로세스를 비교적 가볍게 유지하면서 외부 비디오 컨텐츠가 출력을 안내하도록 허용합니다.
작은 신경 네트워크는 Clean Input 비디오와 세대에 사용되는 시끄러운 잠복의 정렬을 처리합니다. 이 시스템은이 정보를 주입하는 두 가지 방법을 테스트합니다. 다시 압축하기 전에 두 기능 세트를 병합합니다. 프레임별로 기능을 추가합니다. 두 번째 방법은 더 잘 작동하며 저자는 계산 부하를 변경하지 않고 품질 손실을 피합니다.
데이터 및 테스트
테스트에서 사용 된 메트릭은 다음과 같습니다. 아크 페이스이는 참조 이미지와 생성 된 비디오의 각 프레임에서 얼굴 임베딩을 추출한 다음 이들 사이의 평균 코사인 유사성을 계산합니다. 주제 유사성yolo11x 세그먼트를 보내는 것을 통해 디노 2 비교를 위해; 클립 B프롬프트와 생성 된 비디오 사이의 유사성을 측정하는 텍스트 비디오 정렬; Clip-B 다시, 각 프레임과 인접 프레임과 첫 번째 프레임 사이의 유사성을 계산하고 시간적 일관성을 계산합니다. 그리고 동적 학위정의 된대로 vbench.
앞에서 지적한 바와 같이, 기준선 폐쇄 소스 경쟁자는 Hailuo였다. Vidu 2.0; 클링 (1.6); 그리고 피카. 경쟁하는 Foss 프레임 워크는 Vace와 Skyreels-A2였습니다.
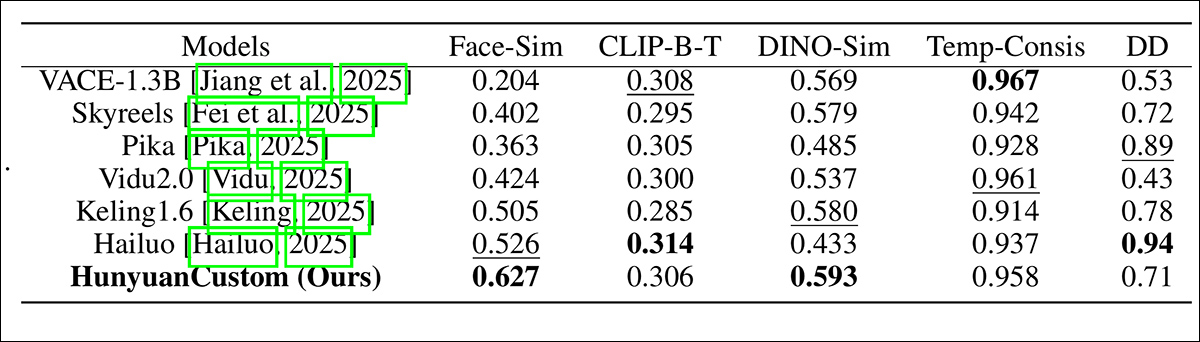
모델 성능 평가 Hunyuancustom과 ID 일관성 (FACE-SIM), 주제 유사성 (DINO-SIM), 텍스트 비디오 정렬 (CLIP-BT), 시간적 일관성 (온도 소송) 및 모션 강도 (DD)의 주요 비디오 사용자 정의 메소드를 비교합니다. 최적의 최적의 결과는 각각 굵게 표시되고 밑줄이 표시됩니다.
이 결과 중 저자는 다음과 같이 말합니다.
‘우리의 [HunyuanCustom] 최고의 ID 일관성과 주제 일관성을 달성합니다. 또한 신속한 결과와 시간적 일관성에 비해 비슷한 결과를 얻습니다. [Hailuo] ID 일관성만으로 텍스트 지침을 잘 따를 수 있기 때문에 최상의 클립 점수가 있습니다. 동적 비용의 관점에서 [Vidu] 그리고 [VACE] 모델의 작은 크기 때문일 수 있습니다. ‘
프로젝트 사이트는 비교 비디오 (레이아웃이 쉽게 비교하기보다는 웹 사이트 미학 용으로 설계된 것 같습니다)와 함께 포화되어 있지만 현재 초기 정 성적 테스트와 관련하여 PDF에서 함께 뭉친 정적 결과와 동등한 비디오는 특징이 없습니다. 여기에 포함 시키지만 독자는 결과에 대한 더 나은 인상을주기 때문에 프로젝트 사이트에서 비디오를 면밀히 조사하도록 권장합니다.
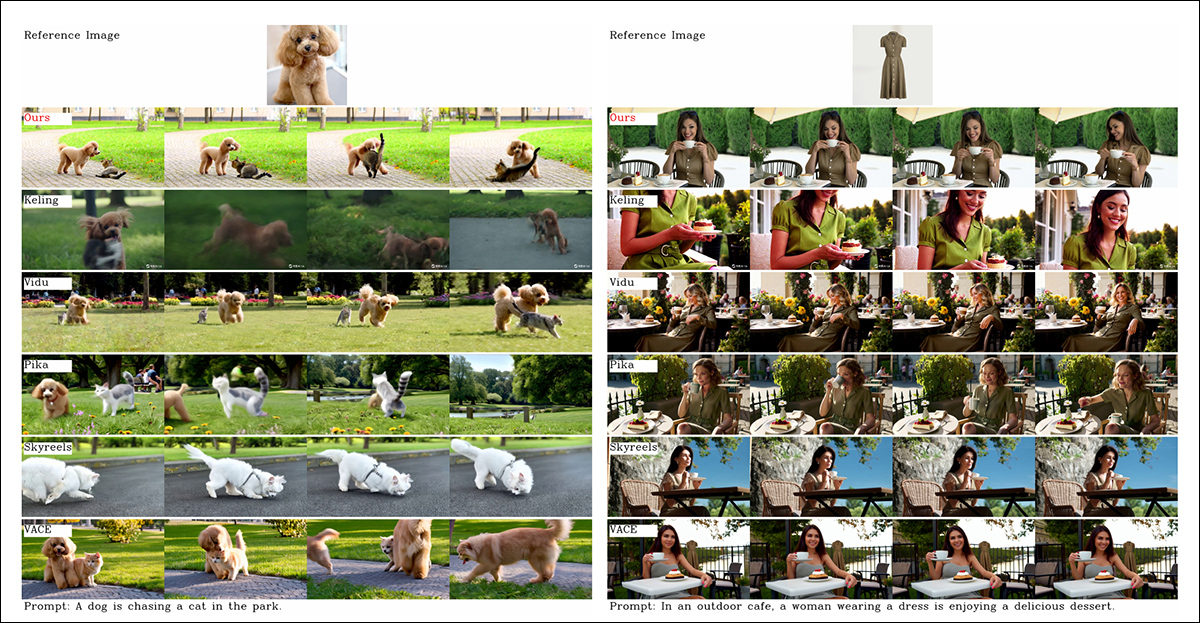
논문에서 객체 중심 비디오 사용자 정의에 대한 비교. 시청자는 (항상 그렇듯이) 더 나은 해상도를 위해 소스 PDF를 참조해야하지만, 프로젝트 사이트의 비디오는이 경우 더 조명적인 리소스 일 수 있습니다.
저자는 여기에 다음과 같습니다.
‘볼 수 있습니다 [Vidu],,, [Skyreels A2] 그리고 우리의 방법은 신속한 정렬 및 주제 일관성에서 비교적 우수한 결과를 얻지 만, 우리의 기본 모델의 좋은 비디오 생성 성능, 즉, 비디오 품질은 Vidu와 Skyreel보다 낫습니다. [Hunyuanvideo-13B].
‘상업용 제품 중 [Kling] 비디오 품질이 양호하고 비디오의 첫 번째 프레임에는 사본-페이스트가 있습니다. [problem]그리고 때로는 주제가 너무 빨리 움직입니다 [blurs]시청 경험이 좋지 않습니다. ‘
저자들은 Pika가 시간적 일관성 측면에서 제대로 수행하지 못하고 자막 아티팩트를 소개합니다 (비디오 클립의 텍스트 요소가 핵심 개념을 오염시킬 수있는 데이터 큐 레이션 불량한 효과).
Hailuo는 얼굴 정체성을 유지하지만 전신 일관성을 보존하지 못합니다. 연구원들은 오픈 소스 방법 중에서, Vace는 정체성 일관성을 유지할 수 없지만 Hunyuancustom은 품질과 다양성을 유지하면서 강력한 정체성 보존으로 비디오를 생성한다고 주장합니다.
다음으로 테스트가 수행되었습니다 다중 개체 비디오 사용자 정의같은 경쟁자에 대항하여. 이전 예에서와 같이, 평평한 PDF 결과는 프로젝트 사이트에서 사용할 수있는 비디오의 인쇄물이 아니지만 제시된 결과 중에서 고유합니다.

다중 개체 비디오 사용자 정의를 사용한 비교. 더 나은 세부 사항과 해상도는 PDF를 참조하십시오.
논문은 다음과 같습니다.
‘[Pika] 지정된 주제를 생성 할 수는 있지만 비디오 프레임에서 불안정성을 나타냅니다. 한 시나리오에서 사라지고 여성이 촉구 된대로 문을 열지 못하는 여성의 경우가 있습니다. [Vidu] 그리고 [VACE] 인간의 정체성을 부분적으로 포착하지만 인간이 아닌 대상에 대한 중요한 세부 사항을 잃어 버려서 비인간 대상을 나타내는 제한을 나타냅니다.
‘[SkyReels A2] 올바른 시나리오에서 칩과 수많은 아티팩트가 눈에 띄는 변화로 심각한 프레임 불안정성을 경험합니다.
‘반면, 우리의 hunyuancustom은 인간과 비인간 주제 정체성을 효과적으로 포착하고, 주어진 프롬프트를 준수하는 비디오를 생성하며, 높은 시각적 품질과 안정성을 유지합니다.’
추가 실험은 ‘가상 인간 광고’였으며, 프레임 워크는 제품을 사람과 통합해야합니다.

질적 테스트 라운드에서 신경 ‘제품 배치’의 예. 더 나은 세부 사항과 해상도는 PDF를 참조하십시오.
이 라운드의 경우 저자는 다음과 같이 말합니다.
‘그만큼 [results] Hunyuancustom은 텍스트를 포함하여 대상 제품의 세부 사항을 보존하면서 인간의 정체성을 효과적으로 유지한다는 것을 보여줍니다.
‘인간과 제품 사이의 상호 작용은 자연스럽게 보이고 비디오는 주어진 프롬프트에 밀접하게 준수하여 광고 비디오를 생성 할 때 Hunyuancustom의 실질적인 잠재력을 강조합니다.’
비디오 결과가 매우 유용한 영역 중 하나는 오디오 중심의 주제 커스터마이징을위한 질적 라운드였습니다. 여기서 캐릭터는 텍스트가 설명 된 장면과 자세에서 해당 오디오를 사용합니다.
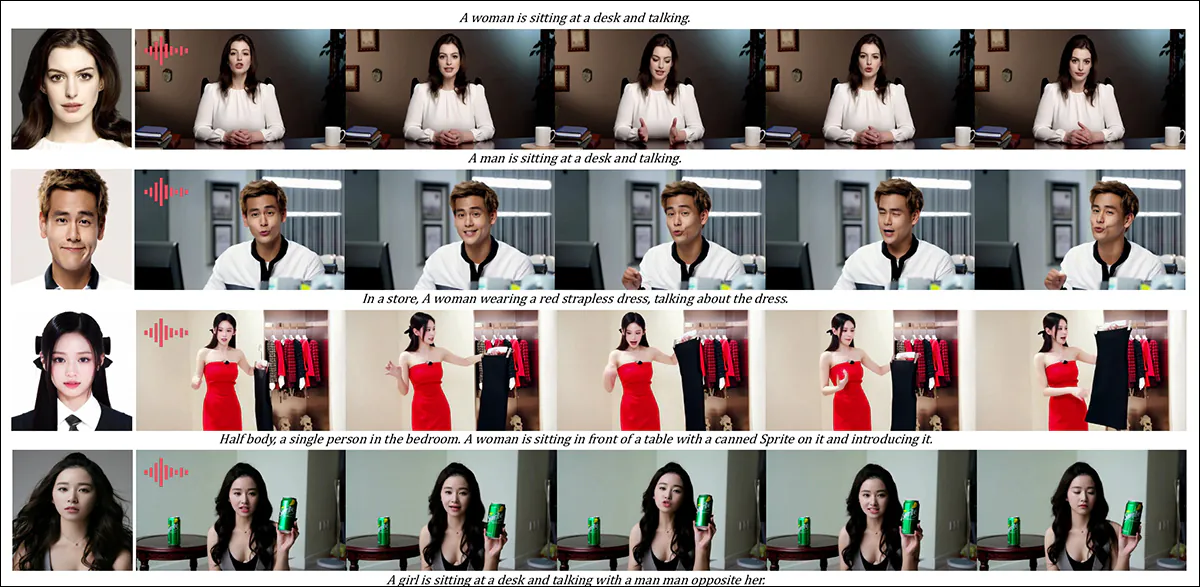
이 경우 비디오 결과가 바람직했을 수도 있지만 오디오 라운드에 대한 부분 결과 – 비디오 결과가 바람직했을 수 있습니다. 이 기사에서는 크고 수용하기가 어렵 기 때문에 PDF 수치의 상단 절반만이 여기에서 재현됩니다. 더 나은 세부 사항과 해상도는 소스 PDF를 참조하십시오.
저자는 다음과 같이 주장합니다.
‘이전의 오디오 중심의 휴먼 애니메이션 방법은 인간 이미지와 오디오를 입력합니다. 여기서 인간 자세, 복장 및 환경이 주어진 이미지와 일치하며 다른 제스처와 환경에서 비디오를 생성 할 수 없습니다. [restrict] 그들의 응용 프로그램.
‘…[Our] Hunyuancustom은 오디오 중심의 휴먼 커스터마이징을 가능하게합니다. 여기서 캐릭터는 텍스트가 설명 된 장면과 자세에서 해당 오디오를 사용하여보다 유연하고 제어 가능한 오디오 중심의 휴먼 애니메이션을 가능하게합니다. ‘
추가 테스트 (모든 세부 사항은 PDF 참조) Vace에 대한 새로운 시스템을 둥글게하고 비디오 주제 교체를 위해 Kling 1.6을 포함했습니다.

비디오 대 비디오 모드에서 주제 교체 테스트. 더 나은 세부 사항과 해상도는 소스 PDF를 참조하십시오.
이 중 새로운 논문에 제시된 마지막 테스트, 연구원들은 다음과 같습니다.
‘Vace는 입력 마스크에 대한 엄격한 준수로 인해 경계 아티팩트로 고통을 겪어 부 자연스러운 대상 모양과 동작 연속성을 방해합니다. [Kling]대조적으로, 대상이 비디오에 직접 겹쳐져 배경과의 통합이 잘못된 카피 페이스트 효과를 나타냅니다.
‘Hunyuancustom은 경계 인공물을 효과적으로 피하고 비디오 배경과 완벽한 통합을 달성하며 강력한 정체성 보존을 유지하여 비디오 편집 작업에서 우수한 성능을 제시합니다.’
결론
이것은 최소한의 매혹적인 릴리스입니다. 최소한의 매혹적인 릴리스는 최소한의 매혹적인 릴리스입니다. 끊임없이 독신적 인 애호가 장면이 최근에 더 불평하고있는 내용을 다루었 기 때문에 립스 동기 부족에 대해 더 불평하기 때문에 Hunyuan Video 및 WAN 2.1과 같은 시스템에서 가능한 증가 된 현실주의에는 새로운 차원의 진실성이 주어질 수 있습니다.
프로젝트 사이트의 거의 모든 비교 비디오 예제의 레이아웃은 이전 경쟁자와 hunyuancustom의 기능을 비교하기가 어렵지만 비디오 합성 공간의 프로젝트는 Kling에 대한 테스트에서 자신을 구덩이에 넣을 수있는 용기가 거의 없다는 점에 유의해야합니다. Tencent는 다소 인상적인 방식 으로이 현직에 대항하는 것으로 보입니다.
* 문제는 일부 비디오가 너무 넓고 짧고 고해상도이므로 VLC 또는 Windows Media Player와 같은 표준 비디오 플레이어에서는 검은 색 화면을 보여주지 않을 것입니다.
2025 년 5 월 8 일 목요일에 처음 출판되었습니다
게시물 Hunyuancustom은 오디오 및 립싱크가 포함 된 단일 이미지 비디오 딥 피케를 제공합니다. 먼저 나타났습니다 Unite.ai.