{kind=link}


이 문서에서는 교육할 수 있는 Windows 기반 소프트웨어를 설치하고 사용하는 방법을 보여줍니다. Hunyuan 비디오 LoRA 모델사용자는 Hunyuan Video 기반 모델에서 사용자 정의 성격을 생성할 수 있습니다.
재생하려면 클릭하세요. 최근 civit.ai 커뮤니티에서 유명인 Hunyuan LoRA가 폭발적으로 증가한 예입니다.
현재 Hunyuan LoRA 모델을 로컬에서 생성하는 가장 인기 있는 두 가지 방법은 다음과 같습니다.
1) 확산 파이프 UI Docker 기반 프레임워크이는 다음에 의존합니다. Linux용 Windows 하위 시스템 (WSL) 일부 프로세스를 처리합니다.
2) 무수비 튜너인기에 새로운 추가 코야 SS 확산 훈련 아키텍처. Musubi Tuner는 Docker가 필요하지 않으며 WSL 또는 기타 Linux 기반 프록시에 의존하지 않습니다. 하지만 Windows에서는 실행하기 어려울 수 있습니다.
따라서 이 실행에서는 Musubi Tuner에 중점을 두고 API 기반 웹 사이트나 Runpod와 같은 상용 GPU 임대 프로세스를 사용하지 않고 Hunyuan LoRA 훈련 및 생성을 위한 완전한 로컬 솔루션을 제공하는 데 중점을 둘 것입니다.
재생하려면 클릭하세요. 이 기사의 Musubi Tuner에 대한 LoRA 교육 샘플입니다. 이 기사를 설명하기 위한 목적으로 묘사된 인물이 부여한 모든 권한입니다.
요구 사항
설치하려면 최소 12GB VRAM(16GB 권장)이 있는 30+/40+ 시리즈 NVIDIA 카드가 장착된 Windows 10 PC가 필요합니다. 이 기사에 사용된 설치는 64GB 용량의 시스템에서 테스트되었습니다. 체계 RAM 및 24GB VRAM을 갖춘 NVIDIA 3090 그래픽 카드. 600GB 이상의 여유 디스크 공간이 있는 파티션에서 Windows 10 Professional을 새로 설치하여 전용 테스트 베드 시스템에서 테스트되었습니다.
경고
Musubi Tuner와 그 필수 구성 요소를 설치하려면 PC의 기본 Windows 설치에 개발자 중심 소프트웨어 및 패키지를 직접 설치해야 합니다. ComfyUI 설치를 고려하면 최종 단계에서 이 프로젝트에는 약 400-500GB의 디스크 공간이 필요합니다. 새로 설치된 테스트 베드 Windows 10 환경에서 여러 번 무사고로 절차를 테스트했지만, 이 지침을 따랐을 때 발생하는 시스템 손상에 대해 저와 Unite.ai 모두 책임을 지지 않습니다. 이런 종류의 설치 절차를 시도하기 전에 중요한 데이터를 백업하는 것이 좋습니다.
고려사항
이 방법이 여전히 유효한가요?
생성 AI 장면은 매우 빠르게 움직이고 있으며 올해 Hunyuan Video LoRA 프레임워크의 더 좋고 효율적인 방법을 기대할 수 있습니다.
…아니면 이번 주에도요! 제가 이 글을 쓰고 있는 동안, 코야/무수비의 개발자가 프로듀싱을 했습니다. 무스비-튜너-gui, Musubi Tuner를 위한 정교한 Gradio GUI:

musubi-tuner-gui가 작동하면 분명히 사용자 친화적인 GUI가 이 기능에서 사용하는 BAT 파일보다 더 좋습니다. 제가 글을 쓰는 동안에는 5일 전에야 온라인에 접속되었으며 성공적으로 사용했다는 사람의 기록을 찾을 수 없습니다.
저장소의 게시물에 따르면 새로운 GUI는 가능한 한 빨리 Musubi Tuner 프로젝트에 직접 롤백될 예정이며, 이로 인해 독립형 GitHub 저장소로서의 현재 존재가 종료됩니다.
현재 설치 지침에 따라 새 GUI는 기존 Musubi 가상 환경에 직접 복제됩니다. 많은 노력에도 불구하고 기존 Musubi 설치와 연결할 수 없습니다. 즉, 실행될 때 엔진이 없다는 것을 알게 됩니다!
GUI가 Musubi Tuner에 통합되면 이런 종류의 문제는 확실히 해결될 것입니다. 비록 저자는 새 프로젝트가 ‘정말 힘들다’고 인정그는 Musubi Tuner에 직접 개발하고 통합하는 것에 대해 낙관적입니다.
이러한 문제(설치 시 기본 경로 및 UV Python 패키지이로 인해 새 릴리스의 특정 절차가 복잡해짐) 더 원활한 Hunyuan Video LoRA 훈련 경험을 위해서는 조금 기다려야 할 것입니다. 즉, 매우 유망해 보입니다!
그러나 기다릴 수 없고 소매를 조금 걷어붙이고 싶다면 지금 바로 Hunyuan 비디오 LoRA 교육을 현지에서 실행할 수 있습니다.
시작해 봅시다.
설치 이유 아무것 베어메탈에서?
(고급 사용자가 아닌 경우 이 단락을 건너뛰세요)
고급 사용자는 가상 환경 대신 베어 메탈 Windows 10 설치에 그렇게 많은 소프트웨어를 설치하기로 선택한 이유가 무엇인지 궁금해할 것입니다. 그 이유는 Linux 기반의 Windows 포트가 필수적이기 때문입니다. 트리톤 패키지 가상 환경에서 작업하는 것이 훨씬 더 어렵습니다. 튜토리얼의 다른 모든 베어메탈 설치는 로컬 하드웨어와 직접 인터페이스해야 하므로 가상 환경에 설치할 수 없습니다.
필수 패키지 및 프로그램 설치
처음 설치해야 하는 프로그램과 패키지의 경우 설치 순서가 중요합니다. 시작해 봅시다.
1: Microsoft 재배포 가능 패키지 다운로드
다음에서 Microsoft 재배포 가능 패키지를 다운로드하여 설치하세요. https://aka.ms/vs/17/release/vc_redist.x64.exe.
이는 간단하고 빠른 설치입니다.

2: Visual Studio 2022 설치
다음에서 Microsoft Visual Studio 2022 Community 에디션을 다운로드하세요. https://visualstudio.microsoft.com/downloads/?cid=learn-onpage-download-install-visual-studio-page-cta
다운로드한 설치 프로그램을 시작합니다.

사용 가능한 모든 패키지가 필요하지 않으므로 설치가 무겁고 시간이 오래 걸립니다. 초기에는 워크로드 열리는 페이지, 체크 C++를 사용한 데스크탑 개발 (아래 이미지 참조).

이제 개별 구성 요소 인터페이스 왼쪽 상단의 탭을 누르고 검색 상자를 사용하여 ‘Windows SDK’를 찾으세요.

기본적으로 윈도우 11 SDK 가 표시되어 있습니다. Windows 10을 사용하는 경우(이 설치 절차는 Windows 11에서 테스트되지 않았습니다.) 위 이미지에 표시된 최신 Windows 10 버전을 선택하세요.
‘C++ CMake’를 검색하여 확인하세요. C++ Windows용 CMake 도구 확인됩니다.

이 설치에는 최소 13GB의 공간이 필요합니다.

Visual Studio가 설치되면 컴퓨터에서 실행을 시도합니다. 완전히 열리게 하세요. Visual Studio의 전체 화면 인터페이스가 마침내 표시되면 프로그램을 닫습니다.
3: 비주얼 스튜디오 2019 설치
Musubi의 후속 패키지 중 일부에는 이전 버전의 Microsoft Visual Studio가 필요하지만 다른 패키지에는 최신 버전이 필요합니다.
따라서 Microsoft(https://visualstudio.microsoft.com/vs/older-downloads/ – 계정 필요) 또는 Techspot(https://www.techspot.com/downloads/7241-visual-studio-2019.html).
Visual Studio 2022와 동일한 옵션을 사용하여 설치합니다(다음을 제외하고 위 절차 참조). 윈도우 SDK Visual Studio 2019 설치 관리자에서 이미 선택되어 있습니다).
Visual Studio 2019 설치 관리자가 설치 시 최신 버전을 이미 인식하고 있음을 알 수 있습니다.

설치가 완료되고 설치된 Visual Studio 2019 애플리케이션을 열었다 닫았으면 Windows 명령 프롬프트(입력 명령 검색 시작에서) 다음을 입력하고 입력합니다.
where cl
결과는 설치된 두 Visual Studio 버전의 알려진 위치여야 합니다.

대신에 얻는다면 INFO: Could not find files for the given pattern(s)참조 경로 확인 아래 이 문서의 섹션을 참조하고 해당 지침을 사용하여 Windows 환경에 관련 Visual Studio 경로를 추가하세요.
다음에 따라 변경된 사항을 저장합니다. 경로 확인 섹션을 확인한 다음 where cl 명령을 다시 시도하십시오.
4: CUDA 11 + 12 툴킷 설치
Musubi에 설치된 다양한 패키지에는 다양한 버전의 패키지가 필요합니다. 엔비디아 쿠다NVIDIA 그래픽 카드에 대한 훈련을 가속화하고 최적화합니다.
Visual Studio 버전을 설치한 이유 첫 번째 NVIDIA CUDA 설치 프로그램이 기존 Visual Studio 설치를 검색하고 통합한다는 것입니다.
다음에서 11+ 시리즈 CUDA 설치 패키지를 다운로드하세요.
https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local (다운로드 ‘exe (로컬’) )
다음에서 12+ 시리즈 CUDA 툴킷 설치 패키지를 다운로드하세요.
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
설치 프로세스는 두 설치 프로그램 모두 동일합니다. Windows 환경 변수에 설치 경로가 있는지 여부에 대한 경고는 무시하세요. 이 문제는 나중에 수동으로 처리하겠습니다.
NVIDIA CUDA 툴킷 V11+ 설치
11+ 시리즈 CUDA 툴킷 설치 프로그램을 시작합니다.


~에 설치 옵션선택하다 사용자 정의(고급) 그리고 진행하세요.

NVIDIA GeForce Experience 옵션을 선택 취소하고 클릭하세요. 다음.

떠나다 설치 위치 선택 기본값(중요):

딸깍 하는 소리 다음 설치를 마치도록 하겠습니다.

설치 프로그램이 제공하는 경고나 참고 사항을 무시하십시오. Nsight 비주얼 스튜디오 우리의 사용 사례에는 필요하지 않은 통합입니다.
NVIDIA CUDA 툴킷 V12+ 설치
다운로드한 별도의 12개 이상의 NVIDIA 툴킷 설치 프로그램에 대해 전체 프로세스를 반복하십시오.

이 버전의 설치 프로세스는 무시할 수 있는 환경 경로에 대한 한 가지 경고를 제외하고 위에 나열된 프로세스(11+ 버전)와 동일합니다.

12+ CUDA 버전 설치가 완료되면 Windows에서 명령 프롬프트를 열고 다음을 입력하고 입력합니다.
nvcc --version
설치된 드라이버 버전에 대한 정보를 확인해야 합니다.

카드가 인식되는지 확인하려면 다음을 입력하고 입력하세요.
nvidia-smi

5: GIT 설치
GIT는 로컬 컴퓨터에 Musubi 저장소 설치를 처리합니다. 다음 위치에서 GIT 설치 프로그램을 다운로드하세요.
https://git-scm.com/downloads/win (‘Windows 설치용 64비트 Git’)

설치 프로그램을 실행합니다:

기본 설정 사용 구성 요소 선택:
기본 편집기를 다음 위치에 두십시오. 정력:

GIT가 브랜치 이름을 결정하도록 합니다.

권장 설정을 사용하세요. 길 환경:

SSH에 권장 설정을 사용합니다.

권장 설정 사용 HTTPS 전송 백엔드:
줄 끝 변환에 권장 설정을 사용합니다.

Windows 기본 콘솔을 터미널 에뮬레이터로 선택합니다.
기본 설정 사용(빨리감기 또는 병합) Git Pull의 경우:

자격 증명 도우미에 Git-Credential Manager(기본 설정)를 사용합니다.

~ 안에 추가 옵션 구성떠나다 파일 시스템 캐싱 활성화 체크하고, 심볼릭 링크 활성화 선택 취소합니다(중앙 집중식 모델 저장소에 대한 하드 링크를 사용하는 고급 사용자가 아닌 경우).

설치를 완료하고 Git이 insta인지 테스트합니다. CMD 창을 열고 다음을 입력하면 올바르게 입력됩니다.
git --version

GitHub 로그인
나중에 GitHub 리포지토리를 복제하려고 하면 GitHub 자격 증명을 요구할 수 있습니다. 이를 예상하려면 Windows 시스템에 설치된 브라우저에서 GitHub 계정에 로그인하세요(필요한 경우 계정 생성). 이런 식으로 0Auth 인증 방법(팝업 창)은 가능한 한 짧은 시간이 소요되어야 합니다.
최초 인증 확인 후에는 자동으로 인증 상태를 유지해야 합니다.
6: CMake 설치
Musubi 설치 프로세스의 일부에는 CMake 3.21 이상이 필요합니다. CMake는 다양한 컴파일러를 조정하고 소스 코드에서 소프트웨어를 컴파일할 수 있는 크로스 플랫폼 개발 아키텍처입니다.
다음에서 다운로드하세요:
https://cmake.org/download/ (‘Windows x64 설치 프로그램’)
설치 프로그램을 실행합니다:

보장하다 PATH 환경 변수에 Cmake를 추가합니다. 확인됩니다.

누르다 다음.

Windows 명령 프롬프트에 다음 명령을 입력하고 입력합니다.
cmake --version
CMake가 성공적으로 설치되면 다음과 같은 내용이 표시됩니다.
cmake version 3.31.4CMake suite maintained and supported by Kitware (kitware.com/cmake).

7: 파이썬 3.10 설치
Python 인터프리터는 이 프로젝트의 핵심입니다. 다음에서 3.10 버전(Musubi 패키지의 다양한 요구 사항을 가장 잘 충족한 버전)을 다운로드하세요.
https://www.python.org/downloads/release/python-3100/ (‘Windows 설치 프로그램(64비트)’)
다운로드 설치 프로그램을 실행하고 기본 설정을 유지합니다.

설치 과정이 끝나면 다음을 클릭하세요. 경로 길이 제한 비활성화 (UAC 관리자 확인 필요):

Windows 명령 프롬프트에 다음을 입력하고 입력합니다.
python --version
이로 인해 다음과 같은 결과가 발생합니다. Python 3.10.0

경로 확인
Musubi 프레임워크의 복제 및 설치와 설치 후 정상적인 작동을 위해서는 해당 구성 요소가 Windows의 여러 중요한 외부 구성 요소, 특히 CUDA에 대한 경로를 알고 있어야 합니다.
따라서 경로 환경을 열고 거기에 모든 필수 구성 요소가 있는지 확인해야 합니다.
Windows 환경 컨트롤에 접근하는 빠른 방법은 다음을 입력하는 것입니다. 시스템 환경 변수 편집 Windows 검색창에

이것을 클릭하면 다음이 열립니다. 시스템 속성 제어판. 오른쪽 하단에는 시스템 속성, 환경 변수 버튼과 창 환경 변수 열립니다. 에서 시스템 변수 이 창의 아래쪽 절반에 있는 패널에서 아래로 스크롤하여 길 두 번 클릭하세요. 그러면 다음과 같은 창이 열립니다. 환경 변수 편집. 변수의 전체 경로를 볼 수 있도록 이 창의 너비를 더 넓게 드래그하십시오.

여기서 중요한 항목은 다음과 같습니다.
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.6binC:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.6libnvvpC:Program FilesNVIDIA GPU Computing ToolkitCUDAv11.8binC:Program FilesNVIDIA GPU Computing ToolkitCUDAv11.8libnvvpC:Program Files (x86)Microsoft Visual Studio2019CommunityVCToolsMSVC14.29.30133binHostx64x64C:Program FilesMicrosoft Visual Studio2022CommunityVCToolsMSVC14.42.34433binHostx64x64C:Program FilesGitcmdC:Program FilesCMakebin
대부분의 경우 올바른 경로 변수가 이미 존재해야 합니다.
클릭하여 누락된 경로를 추가하세요. 새로운 왼쪽에 환경 변수 편집 창을 열고 올바른 경로에 붙여넣습니다.

위에 나열된 경로에서 복사하여 붙여넣지 마십시오. 자신의 Windows 설치에 상응하는 각 경로가 있는지 확인하십시오.
사소한 경로 변형이 있는 경우(특히 Visual Studio 설치의 경우) 위에 나열된 경로를 사용하여 올바른 대상 폴더를 찾으세요(예: x64 ~에 호스트64 귀하의 설치에서. 그런 다음 붙여 넣기 저것들 으로의 경로 환경 변수 편집 창문.
그런 다음 컴퓨터를 다시 시작하십시오.
무수비 설치
PIP 업그레이드
최신 버전의 PIP 설치 프로그램을 사용하면 일부 설치 단계를 원활하게 진행할 수 있습니다. 관리자 권한이 있는 Windows 명령 프롬프트에서(참조: 높이아래), 다음을 입력하고 입력합니다.
pip install --upgrade pip
높이
일부 명령에는 높은 권한이 필요할 수 있습니다(즉, 관리자로 실행하려면). 다음 단계에서 권한에 대한 오류 메시지가 나타나면 명령 프롬프트 창을 닫고 다음을 입력하여 관리자 모드에서 다시 엽니다. 명령 Windows 검색창에 마우스 오른쪽 버튼을 클릭하고 명령 프롬프트 그리고 선택 관리자로 실행:

다음 단계에서는 Windows 명령 프롬프트 대신 Windows Powershell을 사용하겠습니다. 이것을 입력하면 찾을 수 있습니다. 파워셸 Windows 검색 상자에 들어가서 (필요한 경우) 마우스 오른쪽 버튼을 클릭하여 관리자로 실행:

토치 설치
Powershell에서 다음을 입력하고 입력합니다.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
많은 패키지가 설치되는 동안 인내심을 가지십시오.
완료되면 다음을 입력하여 GPU 지원 PyTorch 설치를 확인할 수 있습니다.
python -c "import torch; print(torch.cuda.is_available())"
결과는 다음과 같습니다.
C:WINDOWSsystem32>python -c "import torch;print(torch.cuda.is_available())"True
Windows용 Triton 설치
다음으로, Windows용 트리톤 요소. 관리자 권한 Powershell에서 다음을 입력합니다(한 줄에).
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post8/triton-3.1.0-cp310-cp310-win_amd64.whl
(설치자는 triton-3.1.0-cp310-cp310-win_amd64.whl 아키텍처가 64비트이고 환경이 Python 버전과 일치하는 한 Intel 및 AMD CPU 모두에서 작동합니다.)
실행 후 결과는 다음과 같습니다.
Successfully installed triton-3.1.0
Triton을 Python으로 가져와서 작동하는지 확인할 수 있습니다. 다음 명령을 입력하세요.
python -c "import triton; print('Triton is working')"
다음과 같이 출력되어야 합니다.
Triton is working
Triton이 GPU를 지원하는지 확인하려면 다음을 입력하세요.
python -c "import torch; print(torch.cuda.is_available())"
이로 인해 다음과 같은 결과가 발생합니다. True:

Musubi용 가상 환경 생성
이제부터 추가 소프트웨어를 Python 가상 환경 (또는 벤브). 즉, 다음 소프트웨어를 모두 제거하려면 venv의 설치 폴더를 휴지통으로 드래그하기만 하면 됩니다.
해당 설치 폴더를 만들어 보겠습니다. Musubi 데스크탑에서. 다음 예에서는 이 폴더가 존재한다고 가정합니다. C:Users[Your Profile Name]DesktopMusubi.
Powershell에서 다음을 입력하여 해당 폴더로 이동합니다.
cd C:Users[Your Profile Name]DesktopMusubi
우리는 가상 환경이 우리가 이미 설치한 것(특히 Triton)에 접근할 수 있기를 원합니다. --system-site-packages 깃발. 다음을 입력하세요:
python -m venv --system-site-packages musubi
환경이 생성될 때까지 기다린 후 다음을 입력하여 활성화합니다.
.musubiScriptsactivate
이 시점부터 모든 프롬프트 시작 부분에 (musubi)가 표시된다는 사실을 통해 활성화된 가상 환경에 있음을 알 수 있습니다.

저장소 복제
새로 생성된 항목으로 이동합니다. musubi 폴더(폴더 안에 있음) Musubi 폴더):
cd musubi
이제 올바른 위치에 있으므로 다음 명령을 입력하십시오.
git clone https://github.com/kohya-ss/musubi-tuner.git
복제가 완료될 때까지 기다립니다(오래 걸리지 않습니다).

설치 요구 사항
설치 폴더로 이동합니다:
cd musubi-tuner
입력하다:
pip install -r requirements.txt
많은 설치가 완료될 때까지 기다립니다(시간이 더 오래 걸립니다).

Hunyuan Video Venv에 대한 액세스 자동화
향후 세션을 위해 새 가상 환경을 쉽게 활성화하고 액세스하려면 다음을 메모장에 붙여넣고 이름으로 저장하세요. 활성화.bat다음으로 저장 모든 파일 옵션(아래 이미지 참조).
@echo off
call C:Users[Your Profile Name]DesktopMusubimusubiScriptsactivate
cd C:Users[Your Profile Name]DesktopMusubimusubimusubi-tuner
cmd
(바꾸다 [Your Profile Name]Windows 사용자 프로필의 실제 이름으로)

이 파일을 어느 위치에 저장하는지는 중요하지 않습니다.
이제부터 두 번 클릭하면 됩니다. 활성화.bat 그리고 즉시 일을 시작하세요.

무수비 튜너 사용하기
모델 다운로드
Hunyuan 비디오 LoRA 교육 프로세스에서는 Hunyuan 비디오 LoRA 사전 캐싱 및 교육을 위한 가능한 모든 최적화 옵션을 지원하기 위해 최소 7개 모델을 다운로드해야 합니다. 이들 모델을 모두 합치면 무게가 60GB가 넘습니다.
다운로드에 대한 최신 지침은 다음에서 찾을 수 있습니다. https://github.com/kohya-ss/musubi-tuner?tab=readme-ov-file#model-download
그러나 이 글을 쓰는 시점의 다운로드 지침은 다음과 같습니다.
clip_l.safetensors
llava_llama3_fp16.safetensorsllava_llama3_fp8_scaled.safetensors
다음에서 다운로드할 수 있습니다:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
mp_rank_00_model_states.pt
mp_rank_00_model_states_fp8.ptmp_rank_00_model_states_fp8_map.pt
다음에서 다운로드할 수 있습니다:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/transformers
pytorch_model.pt
다음에서 다운로드할 수 있습니다:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/vae
선택한 디렉토리에 이를 배치할 수 있지만 이후 스크립트와의 일관성을 위해 다음 위치에 배치하겠습니다.
C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunermodels
이는 이 시점 이전의 디렉토리 배열과 일치합니다. 이후의 모든 명령이나 지침은 모델이 있는 위치로 가정합니다. 그리고 교체하는 것을 잊지 마세요 [Your Profile Name] 실제 Windows 프로필 폴더 이름으로.
데이터 세트 준비
이 점에 대한 커뮤니티 논쟁을 무시하고, Hunyuan LoRA의 교육 데이터 세트에는 10~100장의 사진이 필요하다고 말하는 것이 타당합니다. 이미지의 균형이 잘 잡혀 있고 품질이 좋다면 15개의 이미지로도 아주 좋은 결과를 얻을 수 있습니다.
Hunyuan LoRA는 이미지나 매우 짧고 저해상도 비디오 클립, 심지어는 각각의 혼합에 대해 훈련할 수 있습니다. 하지만 비디오 클립을 훈련 데이터로 사용하는 것은 24GB 카드의 경우에도 어렵습니다.
하지만 비디오 클립은 캐릭터가 다음과 같은 경우에만 정말 유용합니다. Hunyuan Video 재단 모델이 알지 못할 정도로 특이한 방식으로 움직입니다. 또는 추측할 수 있습니다.
예로는 Roger Rabbit, 이종형, The Mask, Spider-Man 또는 다음과 같은 특성을 지닌 기타 인물이 있습니다. 고유한 특징적인 움직임.
Hunyuan Video는 이미 평범한 남자와 여자가 어떻게 움직이는지 알고 있기 때문에 설득력 있는 Hunyuan Video LoRA 인간형 캐릭터를 얻기 위해 비디오 클립이 필요하지 않습니다. 그래서 우리는 정적 이미지를 사용할 것입니다.
이미지 준비
버킷리스트
TLDR 버전:
데이터 세트에 대해 모두 동일한 크기의 이미지를 사용하거나 서로 다른 두 크기(예: 512x768px인 이미지 10개와 768x512px인 이미지 10개) 간에 50/50 분할을 사용하는 것이 가장 좋습니다.
이렇게 하지 않더라도 훈련은 잘 진행될 수 있습니다. Hunyuan Video LoRA는 놀라울 정도로 관대할 수 있습니다.
더 긴 버전
Stable Diffusion과 같은 정적 생성 시스템을 위한 Kohya-ss LoRA와 마찬가지로, 버킷팅 다양한 크기의 이미지에 작업 부하를 분산하는 데 사용되므로 훈련 시 메모리 부족 오류를 일으키지 않고 더 큰 이미지를 사용할 수 있습니다. 전체 이미지의 의미적 무결성).
훈련 데이터 세트에 포함된 각 이미지 크기(예: 512x768px)에 대해 해당 크기에 대한 버킷 또는 ‘하위 작업’이 생성됩니다. 따라서 다음과 같은 이미지 분포가 있는 경우 버킷 주의가 불균형해지고 일부 사진이 다른 사진보다 훈련에서 더 많이 고려될 위험이 있습니다.
512x768px 이미지 2개
7x 768x512px 이미지
1x1000x600px 이미지
400x800px 이미지 3개
우리는 버킷 주의가 다음 이미지들 사이에서 불평등하게 나누어져 있음을 볼 수 있습니다.

따라서 하나의 형식 크기를 고수하거나 다양한 크기의 분포를 상대적으로 동일하게 유지하십시오.
두 경우 모두 매우 큰 이미지는 피하세요. 이렇게 하면 학습 속도가 느려지고 이점이 미미해질 수 있습니다.
단순화를 위해 데이터 세트의 모든 사진에 512x768px를 사용했습니다.
부인 성명: 데이터세트에 사용된 모델(사람)은 이 사진을 이러한 목적으로 사용할 수 있는 모든 권한을 나에게 부여했으며 이 기사에 소개된 그녀의 초상을 묘사하는 모든 AI 기반 출력에 대한 승인을 행사했습니다.

내 데이터세트는 PNG 형식의 이미지 40개로 구성되어 있습니다(JPG도 괜찮지만). 내 이미지는 다음 위치에 저장되었습니다. C:UsersMartinDesktopDATASETS_HUNYUANexamplewoman
당신은 은닉처 훈련 이미지 폴더 내의 폴더:

이제 교육을 구성할 특수 파일을 만들어 보겠습니다.
TOML 파일
Hunyuan Video LoRA obt의 훈련 및 사전 캐싱 프로세스 다음과 같은 일반 텍스트 파일의 파일 경로를 확인합니다. .toml 확대.
내 테스트에서 TOML은 C:UsersMartinDesktopDATASETS_HUNYUANtraining.toml에 있습니다.
내 교육 TOML의 내용은 다음과 같습니다.
[general]
resolution = [512, 768]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman"
cache_directory = "C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman\cache"
num_repeats = 1
(이미지 및 캐시 디렉터리의 이중 백슬래시는 항상 필요한 것은 아니지만 경로에 공백이 있는 경우 오류를 방지하는 데 도움이 될 수 있습니다. 저는 단일 전달 및 단일 전달을 사용하는 .toml 파일로 모델을 훈련했습니다. 역슬래시)
우리는에서 볼 수 있습니다 resolution 512px와 768px의 두 가지 해상도가 고려되는 섹션입니다. 이를 512에 그대로 놔도 여전히 좋은 결과를 얻을 수 있습니다.
캡션
훈위안 비디오는 텍스트+비전 기초 모델이므로 이러한 이미지에 대한 설명 캡션이 필요하며 이는 훈련 중에 고려됩니다. 캡션이 없으면 학습 프로세스가 실패합니다.
있다 다수 이 작업에 사용할 수 있는 오픈 소스 캡션 시스템이 있지만 간단하게 유지하고 태그귀 체계. GitHub에 저장되어 있고 처음 실행 시 매우 무거운 딥 러닝 모델을 다운로드하지만 Python 라이브러리와 간단한 GUI를 로드하는 간단한 Windows 실행 파일 형태로 제공됩니다.
Taggui를 시작한 후 파일 > 디렉터리 로드 이미지 데이터 세트로 이동하고 선택적으로 토큰 식별자(이 경우 예시 여성) 모든 캡션에 추가됩니다.

(반드시 꺼주세요. 4비트로 로드 Taggui가 처음 열릴 때 – 이 기능이 켜져 있으면 캡션 작성 중에 오류가 발생합니다)
왼쪽 미리보기 열에서 이미지를 선택하고 Ctrl+A를 눌러 모든 이미지를 선택합니다. 그런 다음 오른쪽에 있는 자동 캡션 시작 버튼을 누릅니다.

오른쪽 열의 작은 CLI에서 Taggui 다운로드 모델을 볼 수 있지만 캡션 작성자를 처음 실행하는 경우에만 해당됩니다. 그렇지 않으면 캡션 미리보기가 표시됩니다.

이제 각 사진에는 이미지 내용에 대한 설명이 포함된 해당 .txt 캡션이 있습니다.

클릭하시면 됩니다 고급 옵션 Taggui에서 캡션의 길이와 스타일을 늘리기 위해 노력했지만 이는 이 연습의 범위를 벗어납니다.
Taggui를 종료하고 다음으로 넘어 갑시다…
잠재 사전 캐싱
훈련 시 과도한 GPU 로드를 방지하려면 두 가지 유형의 사전 캐시 파일을 생성해야 합니다. 하나는 이미지 자체에서 파생된 잠재 이미지를 나타내는 파일이고 다른 하나는 캡션 콘텐츠와 관련된 텍스트 인코딩을 평가하는 파일입니다.
세 가지 프로세스(2x 캐시 + 교육)를 모두 단순화하려면 질문을 하고 필요한 정보를 제공했을 때 프로세스를 수행하는 대화형 .BAT 파일을 사용할 수 있습니다.
잠재 사전 캐싱의 경우 다음 텍스트를 메모장에 복사하고 .BAT 파일로 저장합니다(예: 이름을 다음과 같이 지정). 잠재 precache.bat) 이전과 마찬가지로 드롭다운 메뉴에서 파일 형식을 확인하세요. 다른 이름으로 저장 대화는 모든 파일 (아래 이미지 참조):
@echo off
REM Activate the virtual environment
call C:Users[Your Profile Name]DesktopMusubimusubiScriptsactivate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with latent pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the latent pre-caching script
python C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunercache_latents.py --dataset_config %TOML_PATH% --vae C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunermodelspytorch_model.pt --vae_chunk_size 32 --vae_tiling
) else (
echo Operation canceled.
)
REM Keep the window open
pause
(반드시 교체하세요. [Your Profile Name] 실제 Windows 프로필 폴더 이름으로)

이제 자동 잠재 캐싱을 위해 .BAT 파일을 실행할 수 있습니다.

BAT 파일에서 다양한 질문이 표시되면 데이터 세트, 캐시 폴더 및 TOML 파일의 경로를 붙여넣거나 입력합니다.
텍스트 사전 캐싱
이번에는 텍스트 사전 캐싱을 위한 두 번째 BAT 파일을 만듭니다.
@echo off
REM Activate the virtual environment
call C:Users[Your Profile Name]DesktopMusubimusubiScriptsactivate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with text encoder output pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Use the python executable from the virtual environment
python C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunercache_text_encoder_outputs.py --dataset_config %TOML_PATH% --text_encoder1 C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunermodelsllava_llama3_fp16.safetensors --text_encoder2 C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunermodelsclip_l.safetensors --batch_size 16
) else (
echo Operation canceled.
)
REM Keep the window open
pause
Windows 프로필 이름을 바꾸고 다음 이름으로 저장하세요. 텍스트-cache.bat (또는 원하는 다른 이름)을 이전 BAT 파일의 절차에 따라 편리한 위치에 저장합니다.
이 새로운 BAT 파일을 실행하고 지침을 따르면 필요한 텍스트 인코딩 파일이 은닉처 접는 사람:

Hunyuan 비디오 Lora 훈련
실제 LoRA를 훈련하는 것은 이 두 가지 준비 과정보다 훨씬 더 오랜 시간이 걸립니다.
걱정할 수 있는 여러 변수(예: 배치 크기, 반복, 에포크, 전체 또는 양자화 모델 사용 여부 등)도 있지만 이러한 고려 사항은 다음 날에 미뤄두겠습니다. LoRA 생성의 복잡성.
지금은 선택 사항을 조금 최소화하고 ‘중앙값’ 설정에서 LoRA를 훈련해 보겠습니다.
이번에는 훈련을 시작하기 위해 세 번째 BAT 파일을 생성하겠습니다. 이것을 메모장에 붙여넣고 이전과 같이 BAT 파일로 저장합니다. training.bat (또는 원하는 이름):
@echo off
REM Activate the virtual environment
call C:Users[Your Profile Name]DesktopMusubimusubiScriptsactivate.bat
REM Get user input
set /p DATASET_CONFIG=Enter the path to the dataset configuration file:
set /p EPOCHS=Enter the number of epochs to train:
set /p OUTPUT_NAME=Enter the output model name (e.g., example0001):
set /p LEARNING_RATE=Choose learning rate (1 for 1e-3, 2 for 5e-3, default 1e-3):
if "%LEARNING_RATE%"=="1" set LR=1e-3
if "%LEARNING_RATE%"=="2" set LR=5e-3
if "%LEARNING_RATE%"=="" set LR=1e-3
set /p SAVE_STEPS=How often (in steps) to save preview images:
set /p SAMPLE_PROMPTS=What is the location of the text-prompt file for training previews?
echo You entered:
echo Dataset configuration file: %DATASET_CONFIG%
echo Number of epochs: %EPOCHS%
echo Output name: %OUTPUT_NAME%
echo Learning rate: %LR%
echo Save preview images every %SAVE_STEPS% steps.
echo Text-prompt file: %SAMPLE_PROMPTS%
REM Prepare the command
set CMD=accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunerhv_train_network.py ^
--dit C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunermodelsmp_rank_00_model_states.pt ^
--dataset_config %DATASET_CONFIG% ^
--sdpa ^
--mixed_precision bf16 ^
--fp8_base ^
--optimizer_type adamw8bit ^
--learning_rate %LR% ^
--gradient_checkpointing ^
--max_data_loader_n_workers 2 ^
--persistent_data_loader_workers ^
--network_module=networks.lora ^
--network_dim=32 ^
--timestep_sampling sigmoid ^
--discrete_flow_shift 1.0 ^
--max_train_epochs %EPOCHS% ^
--save_every_n_epochs=1 ^
--seed 42 ^
--output_dir "C:Users[Your Profile Name]DesktopMusubiOutput Models" ^
--output_name %OUTPUT_NAME% ^
--vae C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/pytorch_model.pt ^
--vae_chunk_size 32 ^
--vae_spatial_tile_sample_min_size 128 ^
--text_encoder1 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/llava_llama3_fp16.safetensors ^
--text_encoder2 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/clip_l.safetensors ^
--sample_prompts %SAMPLE_PROMPTS% ^
--sample_every_n_steps %SAVE_STEPS% ^
--sample_at_first
echo The following command will be executed:
echo %CMD%
set /p CONFIRM=Do you want to proceed with training (y/n)?
if /i "%CONFIRM%"=="y" (
%CMD%
) else (
echo Operation canceled.
)
REM Keep the window open
cmd /k
평소와 같이 모든 인스턴스를 교체하십시오.에프 [Your Profile Name] 올바른 Windows 프로필 이름을 사용하세요.
디렉토리가 C:Users[Your Profile Name]DesktopMusubiOutput Models 존재하지 않는 경우 해당 위치에 생성합니다.
훈련 미리보기
최근 Musubi 트레이너에 활성화된 매우 기본적인 훈련 미리보기 기능이 있습니다. 이 기능을 사용하면 훈련 모델을 강제로 일시 중지하고 저장한 프롬프트를 기반으로 이미지를 생성할 수 있습니다. 자동으로 생성된 폴더에 저장됩니다. 견본훈련된 모델이 저장된 것과 동일한 디렉터리에 있습니다.

이를 활성화하려면 마지막 프롬프트 하나를 텍스트 파일로 저장해야 합니다. 우리가 만든 교육 BAT는 이 파일의 위치를 입력하도록 요청합니다. 따라서 프롬프트 파일의 이름을 원하는 대로 지정하고 어디에든 저장할 수 있습니다.
다음은 훈련 루틴에서 요청할 때 세 가지 다른 이미지를 출력하는 파일에 대한 몇 가지 프롬프트 예입니다.

위의 예에서 볼 수 있듯이 프롬프트 끝에 이미지에 영향을 주는 플래그를 넣을 수 있습니다.
-w는 너비 (설정되지 않은 경우 기본값은 256px입니다. 문서)
-그의 키 (설정되지 않은 경우 기본값은 256px)
-f는 프레임 수. 1로 설정하면 이미지가 생성됩니다. 하나 이상, 비디오.
–d는 시드입니다. 설정하지 않으면 무작위입니다. 하지만 하나의 프롬프트가 진화하는 것을 보도록 설정해야 합니다.
–s는 생성 단계 수이며 기본값은 20입니다.
보다 공식 문서 추가 플래그의 경우.
훈련 미리 보기를 통해 훈련을 취소하고 데이터 또는 설정을 다시 고려하게 만드는 몇 가지 문제를 신속하게 확인할 수 있으므로 시간이 절약되지만 추가 메시지가 나타날 때마다 훈련 속도가 조금 더 느려진다는 점을 기억하십시오.
또한 훈련 미리보기 이미지의 너비와 높이(위에 나열된 플래그에 설정된 대로)가 클수록 훈련 속도가 더 느려집니다.
교육 BAT 파일을 실행합니다.
질문 #1 ‘데이터세트 구성 경로를 입력하세요. TOML 파일에 올바른 경로를 붙여넣거나 입력하세요.
질문 #2 ‘훈련할 에포크 수를 입력하세요’입니다. 이는 이미지의 양과 품질은 물론 캡션 및 기타 요소의 영향을 받기 때문에 시행착오를 거쳐야 하는 변수입니다. 일반적으로 너무 낮은 것보다 너무 높게 설정하는 것이 가장 좋습니다. 모델이 충분히 발전했다고 생각되면 훈련 창에서 Ctrl+C를 눌러 언제든지 훈련을 중지할 수 있기 때문입니다. 처음에는 100으로 설정하고 어떻게 진행되는지 확인하세요.
질문 #3 ‘출력 모델명을 입력하세요’ 입니다. 모델 이름을 지정하세요! 이름을 합리적으로 짧고 단순하게 유지하는 것이 가장 좋습니다.
질문 #4 ‘학습률 선택’이며 기본값은 1e-3(옵션 1)입니다. 추가 경험이 있을 때까지 시작하기 좋은 곳입니다.
질문 #5 미리보기 이미지를 저장하는 빈도(단계별)입니다. 이 값을 너무 낮게 설정하면 미리보기 이미지 저장 사이에 거의 진행되지 않아 훈련 속도가 느려집니다.
질문 #6 교육 미리보기를 위한 텍스트 프롬프트 파일의 위치는 무엇입니까?’입니다. 프롬프트 텍스트 파일의 경로를 붙여넣거나 입력합니다.
그런 다음 BAT는 Hunyuan 모델에 보낼 명령을 표시하고 계속 진행할지 여부(y/n)를 묻습니다.
계속해서 훈련을 시작하세요:
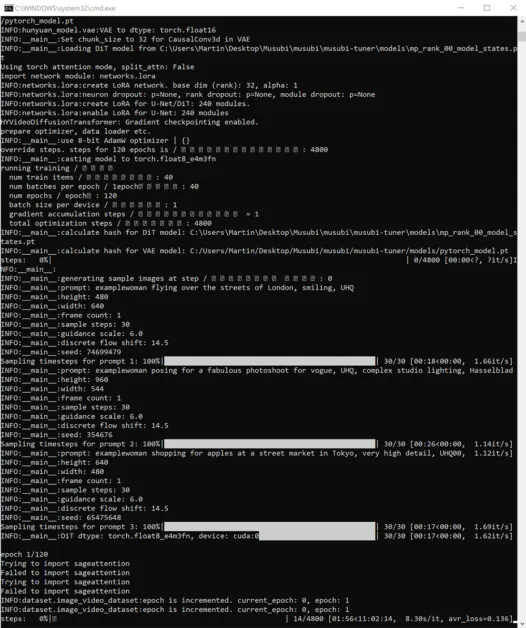
이 시간 동안 Windows 작업 관리자 성능 탭의 GPU 섹션을 확인하면 프로세스가 약 16GB의 VRAM을 사용하는 것을 볼 수 있습니다.

이는 다수의 NVIDIA 그래픽 카드에서 사용할 수 있는 VRAM의 양이고 업스트림 코드는 이러한 카드를 소유한 사용자의 이익을 위해 작업을 16GB에 맞추도록 최적화되었을 수 있으므로 임의의 수치가 아닐 수 있습니다.
즉, 훈련 명령에 더 많은 플래그를 보내면 이 사용량을 높이는 것은 매우 쉽습니다.
훈련 중에는 CMD 창의 오른쪽 하단에 훈련이 시작된 이후 경과한 시간에 대한 수치와 총 훈련 시간의 추정치가 표시됩니다(플래그 세트, 훈련 이미지 수에 따라 크게 달라짐). , 훈련 미리보기 이미지 수 및 기타 여러 요인).

일반적인 훈련 시간은 사용 가능한 하드웨어, 이미지 수, 플래그 설정 및 기타 요인에 따라 중앙값 설정에서 약 3~4시간입니다.
Hunyuan 비디오에서 훈련된 LoRA 모델 사용
체크포인트 선택
훈련이 끝나면 각 훈련 에포크에 대한 모델 체크포인트가 제공됩니다.

이 저장 빈도는 사용자가 원하는 대로 저장 빈도를 변경하여 변경할 수 있습니다. --save_every_n_epochs [N] 교육 BAT 파일의 번호입니다. BAT로 교육을 설정할 때 단계당 저장 횟수를 낮게 추가한 경우 저장된 체크포인트 파일 수가 많아집니다.
어떤 체크포인트를 선택해야 할까요?
앞서 언급했듯이 가장 먼저 훈련된 모델은 가장 유연하며, 나중에 체크포인트가 가장 세부적인 정보를 제공할 수 있습니다. 이러한 요소를 테스트하는 유일한 방법은 일부 LoRA를 실행하고 몇 가지 비디오를 생성하는 것입니다. 이러한 방식으로 어떤 체크포인트가 가장 생산적이고 유연성과 충실도 사이의 최상의 균형을 나타내는지 알 수 있습니다.
ComfyUI
현재 Hunyuan Video LoRA를 사용하기 위한 가장 인기 있는(유일한 것은 아니지만) 환경은 다음과 같습니다. ComfyUI웹 브라우저에서 실행되는 정교한 Gradio 인터페이스를 갖춘 노드 기반 편집기입니다.

출처: https://github.com/comfyanonymous/ComfyUI
설치 지침은 간단하고 공식 GitHub 저장소에서 사용 가능 (추가 모델을 다운로드해야 합니다).
ComfyUI용 모델 변환
훈련된 모델은 대부분의 ComfyUI 구현과 호환되지 않는 (디퓨저) 형식으로 저장됩니다. Musubi는 모델을 ComfyUI 호환 형식으로 변환할 수 있습니다. 이를 구현하기 위해 BAT 파일을 설정해 보겠습니다.
이 BAT를 실행하기 전에 C:Users[Your Profile Name]DesktopMusubiCONVERTED 스크립트가 예상하는 폴더입니다.
@echo off
REM Activate the virtual environment
call C:Users[Your Profile Name]DesktopMusubimusubiScriptsactivate.bat
:START
REM Get user input
set /p INPUT_PATH=Enter the path to the input Musubi safetensors file (or type "exit" to quit):
REM Exit if the user types "exit"
if /i "%INPUT_PATH%"=="exit" goto END
REM Extract the file name from the input path and append 'converted' to it
for %%F in ("%INPUT_PATH%") do set FILENAME=%%~nF
set OUTPUT_PATH=C:Users[Your Profile Name]DesktopMusubiOutput ModelsCONVERTED%FILENAME%_converted.safetensors
set TARGET=other
echo You entered:
echo Input file: %INPUT_PATH%
echo Output file: %OUTPUT_PATH%
echo Target format: %TARGET%
set /p CONFIRM=Do you want to proceed with the conversion (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the conversion script with correctly quoted paths
python C:Users[Your Profile Name]DesktopMusubimusubimusubi-tunerconvert_lora.py --input "%INPUT_PATH%" --output "%OUTPUT_PATH%" --target %TARGET%
echo Conversion complete.
) else (
echo Operation canceled.
)
REM Return to start for another file
goto START
:END
REM Keep the window open
echo Exiting the script.
pause
이전 BAT 파일과 마찬가지로 스크립트를 메모장에서 ‘모든 파일’로 저장하고 이름을 지정합니다. 변환.bat (또는 당신이 좋아하는 것).
저장한 후 새 BAT 파일을 두 번 클릭하면 변환할 파일의 위치를 묻는 메시지가 표시됩니다.

변환하려는 훈련된 파일의 경로를 붙여넣거나 입력하고 yEnter 키를 누릅니다.
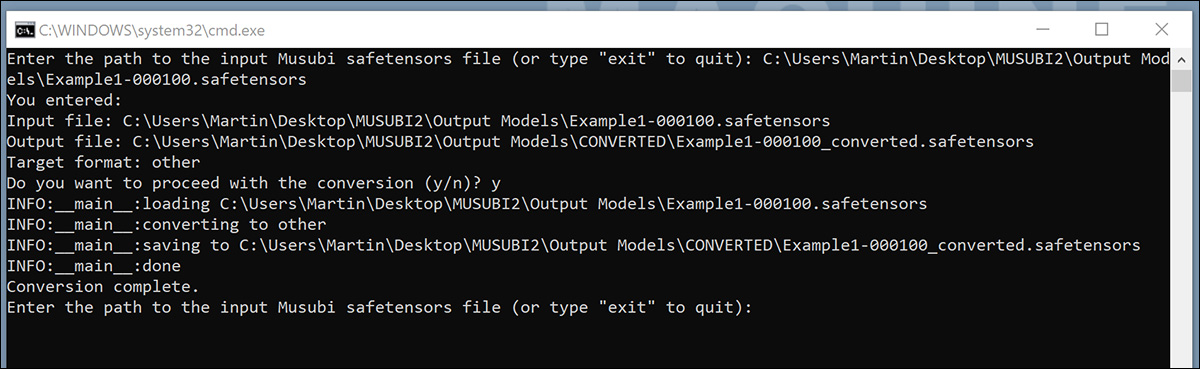
변환된 LoRA를 전환됨 폴더가 있으면 스크립트는 다른 파일을 변환할지 묻습니다. ComfyUI에서 여러 체크포인트를 테스트하려면 선택한 모델을 변환하세요.
충분한 체크포인트를 변환했으면 BAT 명령 창을 닫습니다.
이제 변환된 모델을 ComfyUI 설치의 modelsloras 폴더에 복사할 수 있습니다.
일반적으로 올바른 위치는 다음과 같습니다.
C:Users[Your Profile Name]DesktopComfyUImodelsloras
ComfyUI에서 Hunyuan 비디오 LoRA 만들기
처음에는 ComfyUI의 노드 기반 작업 흐름이 복잡해 보이지만 다른 전문 사용자의 설정은 (다른 사용자의 ComfyUI로 만든) 이미지를 ComfyUI 창으로 직접 드래그하여 로드할 수 있습니다. 워크플로는 수동으로 가져오거나 ComfyUI 창으로 드래그할 수 있는 JSON 파일로 내보낼 수도 있습니다.
일부 가져온 워크플로에는 설치에 존재하지 않을 수 있는 종속성이 있을 수 있습니다. 따라서 설치 ComfyUI 관리자누락된 모듈을 자동으로 가져올 수 있습니다.

출처: https://github.com/ltdrdata/ComfyUI-Manager
이 튜토리얼의 모델에서 비디오를 생성하는 데 사용되는 워크플로 중 하나를 로드하려면 다운로드하세요. 이 JSON 파일 그리고 이를 ComfyUI 창으로 드래그합니다. (Hunyuan Video를 채택한 다양한 Reddit 및 Discord 커뮤니티에서 훨씬 더 나은 작업 흐름 예제를 사용할 수 있고 내 예제도 이 중 하나를 채택했습니다.)
이곳은 ComfyUI 사용에 대한 확장 튜토리얼을 위한 장소는 아니지만, 위에서 링크한 JSON 레이아웃을 다운로드하여 사용할 경우 출력에 영향을 미치는 몇 가지 중요한 매개변수에 대해 언급할 가치가 있습니다.

1) 너비와 높이
이미지가 클수록 생성 시간이 길어지고 메모리 부족(OOM) 오류가 발생할 위험이 높아집니다.
2) 길이
이는 프레임 수에 대한 수치입니다. 프레임 속도에 따라 추가되는 시간(초)입니다(이 레이아웃에서는 30fps로 설정됨). fps를 기준으로 초>프레임을 변환할 수 있습니다. 옴니계산기에서.
3) 배치 크기
배치 크기를 높게 설정할수록 결과는 더 빨리 나올 수 있지만 VRAM의 부담은 커집니다. 이 값을 너무 높게 설정하면 OOM이 발생할 수 있습니다.
4) 생성 후 제어
이것은 무작위 시드를 제어합니다. 이 하위 노드에 대한 옵션은 다음과 같습니다. 결정된, 증가, 감소 그리고 무작위화하다. 에 놔두면 결정된 텍스트 프롬프트를 변경하지 않으면 매번 동일한 이미지가 표시됩니다. 텍스트 프롬프트를 수정하면 이미지가 제한적으로 변경됩니다. 그만큼 증가 그리고 감소 설정을 사용하면 근처의 시드 값을 탐색할 수 있으며, 무작위화하다 프롬프트에 대한 완전히 새로운 해석을 제공합니다.
5) 로라 이름
생성을 시도하기 전에 여기에서 설치된 모델을 직접 선택해야 합니다.
6) 토큰
토큰을 사용하여 개념을 트리거하도록 모델을 훈련한 경우(예: ‘예인’) 프롬프트에 해당 트리거 단어를 입력하세요.
7) 단계
이는 시스템이 확산 프로세스에 적용할 단계 수를 나타냅니다. 단계가 높을수록 더 나은 세부 정보를 얻을 수 있지만 이 접근 방식이 얼마나 효과적인지에 대한 상한선이 있으며 해당 임계값을 찾기 어려울 수 있습니다. 일반적인 단계 범위는 약 20-30입니다.
8) 타일 크기
이는 생성 중 한 번에 처리되는 정보의 양을 정의합니다. 기본적으로 256으로 설정되어 있습니다. 높이면 생성 속도가 빨라질 수 있지만 너무 높게 올리면 긴 프로세스의 마지막 단계에 도달하므로 특히 실망스러운 OOM 경험을 초래할 수 있습니다.
9) 시간적 중첩
Hunyuan 비디오 세대의 사람들은 이 값이 너무 낮게 설정되면 ‘고스팅’ 또는 설득력 없는 움직임으로 이어질 수 있습니다. 일반적으로 더 나은 움직임을 생성하려면 프레임 수보다 높은 값으로 설정해야 한다는 것이 현재 통념입니다.
결론
ComfyUI 사용에 대한 추가 탐색은 이 기사의 범위를 벗어나지만 Reddit 및 Discords의 커뮤니티 경험은 학습 곡선을 완화할 수 있으며 몇 가지 방법이 있습니다. 온라인 가이드 기본을 소개하는 것입니다.
2025년 1월 23일 목요일 첫 게시
게시물 Hunyuan 비디오 LoRA 모델을 훈련하고 사용하는 방법 처음 등장한 Unite.AI.