{kind=link}


생성 AI가 공익을 얻기 시작한 이후, 컴퓨터 비전 연구 분야는 물리 법칙을 이해하고 복제 할 수있는 AI 모델 개발에 대한 관심을 높였습니다. 그러나 중력 및 중력과 같은 현상을 시뮬레이션하기 위해 기계 학습 시스템을 가르치는 과제 액체 역학 적어도 지난 5 년.
부터 잠복 확산 모델 (LDMS)는 2022 년에 생성 AI 장면을 지배하게되었고, 연구원들은 점점 더 집중하고 있습니다 LDM 아키텍처의 물리적 현상을 이해하고 재현 할 수있는 제한된 용량. 이제이 문제는 OpenAI의 생성 비디오 모델의 획기적인 개발로 추가 명성을 얻었습니다. 소라, 그리고 (아마도) 오픈 소스의 (최근에) 더 최근의 출시 동영상 모델 후유아 비디오 그리고 WAN 2.1.
심하게 반영합니다
물리학에 대한 LDM 이해를 향상시키는 것을 목표로하는 대부분의 연구는 보행 시뮬레이션, 입자 물리학 및 뉴턴 운동의 기타 측면과 같은 영역에 중점을 두었습니다. 기본 물리적 행동의 부정확성은 AI 생성 비디오의 진위를 즉시 손상시킬 것이기 때문에 이러한 영역은 주목을 끌었습니다.
그러나 작지만 성장하는 연구 가닥은 LDM의 가장 큰 약점 중 하나에 집중합니다. 상대적으로 무능력 정확한 생산 반사.

2025 년 1 월 논문에서 ‘현실을 반영 : 확산 모델이 충실한 거울 반사를 생성 할 수있게합니다’, ‘반사 실패’와 연구원의 접근법의 예. 출처 : https://arxiv.org/pdf/2409.14677
이 문제는 CGI 시대에도 도전이었으며 비디오 게임 분야에 남아 있습니다. 광선 추적 알고리즘은 표면과 상호 작용할 때 빛의 경로를 시뮬레이션합니다. Ray-Tracing은 가상 광선이 어떻게 튀어 나오거나 물체를 통과하여 현실적인 반사, 굴절 및 그림자를 만드는 방법을 계산합니다.
그러나 각 추가 바운스는 계산 비용을 크게 증가시키기 때문에 실시간 응용 프로그램은 허용 광선 바운스의 수를 제한하여 정확도에 대기 시간을 트레이드 오프해야합니다.
![1960 년대에 처음 개발 된 기술과 원칙을 사용하여 1982-93 년 사이에 완료 된 기술과 원리를 사용하여 전통적인 3D 기반 (IE, CGI) 시나리오에서 가상으로 계산 된 라이트 빔의 표현 (Tron 사이의 범위 [1982] 그리고 쥬라기 공원 [1993]. 출처 : https://www.unrealengine.com/en-us/explainers/ray-tracing/what-is-real-time-ray-tracing](https://www.unite.ai/wp-content/uploads/2025/04/ray-tracing.jpg)
1960 년대에 처음 개발 된 기술과 원칙을 사용하여 1982-93 년 사이 ( ‘Tron’사이의 범위를 사용하는 기술과 원리를 사용하여 전통적인 3D 기반 (IE, CGI) 시나리오에서 가상으로 계산 된 조명 빔의 표현. [1982] 그리고 ‘Jurassic Park’ [1993]. 출처 : https://www.unrealengine.com/en-us/explainers/ray-tracing/what-is-real-time-ray-tracing
예를 들어, 거울 앞에서 크롬 주전자를 묘사하는 것은 반사 표면 사이에 광선이 반복적으로 반복되는 광선 추적 공정을 포함하여 최종 이미지에 대한 실질적인 이점이 거의없는 거의 무한 루프를 생성 할 수 있습니다. 대부분의 경우, 2 ~ 3 바운스의 반사 깊이는 이미 시청자가 인식 할 수있는 것을 초과합니다. 단일 바운스는 빛이 눈에 띄는 반사를 형성하기 위해 적어도 두 번의 여정을 완료해야하기 때문에 검은 거울을 초래할 것입니다.
각 추가 바운스는 계산 비용이 급격히 증가하고 종종 렌더링 시간이 두 배로 증가하여 반사를 더 빨리 처리합니다. 가장 중요한 기회 중 하나 광선 추적 렌더링 품질을 향상시킵니다.
당연히, 반사는 발생하며, 비 후시 거리의 반사 표면이나 전장과 같은 훨씬 덜 명백한 시나리오에서, 반사가 발생하며, 훨씬 덜 명백한 시나리오에서; 상점 창이나 유리 출입구에서 반대 거리의 반사; 또는 객체와 환경이 나타나야 할 수있는 묘사 된 문자 안경에서.

‘The Matrix'(1999)의 상징적 인 장면을위한 전통적인 합성을 통해 달성 된 시뮬레이션 된 트윈 반사.
이미지 문제
이러한 이유로, 확산 모델의 출현 이전에 인기있는 프레임 워크는 신경 방사 분야 (NERF) 및와 같은 최근의 도전자 가우스 스플릿 자연스럽게 성찰을 제정하기위한 자신의 투쟁을 유지했습니다.
그만큼 심판2-Nerf 프로젝트 (아래 그림)는 유리 케이스가 포함 된 장면에 대한 NERF 기반 모델링 방법을 제안했습니다. 이 방법에서, 굴절 및 반사는 시청자의 관점과 의존적이고 독립적 인 요소를 사용하여 모델링되었다. 이 접근법을 통해 연구원들은 굴절이 발생한 표면, 특히 유리 표면을 추정하고 직접 및 반사 된 조명 성분의 분리 및 모델링을 가능하게했습니다.

ref2nerf 논문의 예. 출처 : https://arxiv.org/pdf/2311.17116
지난 4-5 년간의 다른 NERF를 향한 반사 솔루션이 포함되었습니다. 성,,, 현실을 반영합니다및 메타의 2024 평면 반사 인식 신경 방사 분야 프로젝트.
GSPLAT의 경우 미러 -3dgs,,, 반사 가우시안 플래팅그리고 refgaussian 2023 년 반사 문제에 관한 솔루션을 제공했습니다. Nero 프로젝트 반사 품질을 신경 표현에 통합하는 맞춤형 방법을 제안했습니다.
미러버스
반사 논리를 존중하기 위해 확산 모델을 얻는 것은 가우스 스플 래팅 및 NERF와 같은 명시 적으로 구조적, 비 규모의 접근법보다 더 어렵습니다. 확산 모델에서, 훈련 데이터에 광범위한 시나리오에 걸쳐 많은 다양한 예제가 포함되어 있으므로 원래 데이터 세트의 분포와 품질에 크게 의존하는 경우 이러한 종류의 규칙은 확실하게 내장 될 수 있습니다.
전통적으로 이런 종류의 특정 행동을 추가하는 것은 로라 또는 미세 조정 기본 모델의; 그러나 LORA가 자체 교육 데이터에 대한 출력을 왜곡하는 경향이 있는데, 프롬프트 없이도 자체 교육 데이터에 대한 출력을 왜곡하는 경향이있는 반면, 미세 조정은 비싸지 않은 것 외에도 주류에서 돌이킬 수없는 주요 모델을 포크 할 수 있으며, 어떤 주요 모델을 포크 할 수 있으며, 어떤 관련 사용자 정의 도구를 제공 할 수 있기 때문입니다. 다른 원래 모델을 포함한 모델의 변형.
일반적으로 확산 모델을 개선하려면 훈련 데이터가 반사 물리학에 더 큰주의를 기울여야합니다. 그러나 다른 많은 분야들도 비슷한 특별한 관심이 필요합니다. 사용자 지정 큐 레이션이 비싸고 어려운 초 저격 데이터 세트의 맥락에서 이러한 방식으로 모든 약점을 해결하는 것은 실용적이지 않습니다.
그럼에도 불구하고, LDM 반사 문제에 대한 해결책은 계속해서 나타납니다. 최근 인도의 노력은 다음과 같습니다 미러버스 확산 연구 에서이 특별한 도전에서 최첨단을 개선 할 수있는 개선 된 데이터 세트 및 교육 방법을 제공하는 프로젝트.

가장 오른쪽으로, Mirrorverse의 결과는 두 개의 이전 접근법 (중앙 두 열)에 맞서 싸웠습니다. 출처 : https://arxiv.org/pdf/2504.15397
위의 예에서 볼 수 있듯이 (새로운 연구의 PDF의 기능 이미지) Mirrorverse는 동일한 문제를 해결하는 최근 오퍼링을 향상 시키지만 완벽하지는 않습니다.
오른쪽 상단 이미지에서, 우리는 세라믹 항아리가 어디에 있어야하는지의 오른쪽에 있으며, 아래 이미지에서 기술적으로 컵의 반사를 특징으로하지 않아야합니다. 부정확 한 반사는 자연적인 반사 각도의 논리에 대해 오른쪽 영역으로 삐걱 거리고 있습니다.
따라서 우리는 확산 기반 반사의 현재 최신 기술을 나타낼 수 있기 때문에 새로운 방법을 살펴볼 것이지만, 반사율의 필수 데이터 예는 특정 행동 및 시나리오와 함께 얽힐 가능성이 높기 때문에 잠재적 인 확산 모델, 정적 및 비디오 모두에 대한 문제가 될 수있는 정도를 설명하기 위해서도 마찬가지로 새로운 방법을 살펴볼 것입니다.
따라서 LDM의 이러한 특정 기능은 NERF, GSPLAT 및 기존 CGI와 같은 구조 별 접근 방식에 미치지 못할 수 있습니다.
그만큼 새로운 종이 제목이 있습니다 Mirrorverse : 확산 모델을 푸시하여 세상을 현실적으로 반영합니다Bangalore의 Vision and AI Lab, IISC 방갈로르 및 삼성 R & D 연구소의 3 명의 연구원에서 나왔습니다. 종이에는 an이 있습니다 관련 프로젝트 페이지,뿐만 아니라 포옹 얼굴의 데이터 세트소스 코드와 함께 Github에서 출시되었습니다.
방법
연구원들은 처음부터 안정적인 확산과 같은 모델이 어려움을 지적합니다. 유량 반사 기반 프롬프트를 존중하여 문제를 교묘하게 설명합니다.

논문에서 : 현재 최첨단 텍스트-이미지 모델, SD3.5 및 Flux는 장면에서이를 생성하라는 메시지가 표시 될 때 일관되고 기하학적으로 정확한 반사를 생성하는 데 중요한 과제를 나타냅니다.
연구원들은 개발했다 mirrorfusion 2.0합성 이미지에서 미러 반사의 광도주의와 기하학적 정확도를 향상시키기위한 확산 기반 생성 모델. 이 모델 교육은 연구원의 새로 선별 된 데이터 세트를 기반으로했습니다. mirrorgen2다음을 해결하도록 설계되었습니다 일반화 이전 접근법에서 관찰 된 약점.
Mirrorgen2는 도입하여 초기 방법론을 확장합니다 임의의 객체 포지셔닝,,, 무작위 회전그리고 명백한 객체 접지거울 표면에 비해 더 넓은 범위의 객체 포즈와 배치에 걸쳐 반사가 그럴듯하게 유지되도록하는 목표로.
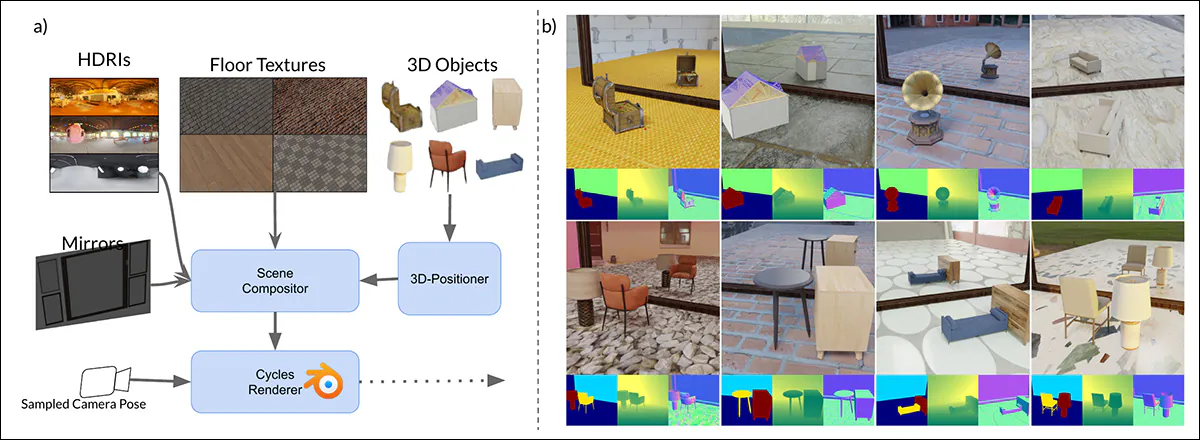
Mirrorverse에서 합성 데이터 생성을위한 스키마 : 데이터 세트 생성 파이프 라인은 3D 위치를 사용하여 장면 내에서 무작위로 위치, 회전 및 접지 객체를 무작위로 포지셔닝, 회전 및 접지에 의해 적용되었습니다. 객체는 또한 의미 적으로 일관된 조합으로 짝을 이루어 복잡한 공간 관계와 폐색을 시뮬레이션하여 데이터 세트가 다중 객체 장면에서보다 현실적인 상호 작용을 캡처 할 수 있습니다.
복잡한 공간 배열을 처리하는 모델의 능력을 더욱 강화하기 위해 MirrorGen2 파이프 라인은 페어링 객체 장면을 사용하여 시스템을 더 잘 할 수 있습니다 반사 설정에서 여러 요소들 사이의 폐색과 상호 작용을 나타냅니다.
논문은 다음과 같습니다.
‘카테고리는 수동으로 짝을 이루어 의미 론적 일관성을 보장합니다 (예 : 의자와 테이블과 쌍을 이루십시오. 렌더링 중에, 1 차를 포지셔닝하고 회전시킨 후 [object]추가 [object] 쌍을 이루는 카테고리에서 겹치는 범주가 겹쳐지고 배열되어 겹치는 것을 방지하여 장면 내에서 뚜렷한 공간 영역을 보장합니다. ‘
명백한 객체 접지와 관련하여, 여기서 저자들은 생성 된 객체가 출력 합성 데이터에서 부적절하게 ‘호버링’하기보다는 합성 데이터가 부적절하게 ‘고정’되었음을 보장했으며, 이는 합성 데이터가 규모로 또는 자동화 된 방법으로 생성 될 때 발생할 수 있습니다.
데이터 세트 혁신은 논문의 참신함의 핵심이므로, 우리는이 섹션 의이 섹션에서 평소보다 일찍 진행할 것입니다.
데이터 및 테스트
synmirrorv2
연구원의 synmirrorv2 데이터 세트는 미러 반사 훈련 데이터의 다양성과 사실주의를 개선하기 위해 고안되었습니다. 우편 그리고 아마존 버클리 물체 (ABO) 데이터 세트, 이러한 선택이 이후에 개선되었습니다 객체 3DITV1의 필터링 프로세스뿐만 아니라 mirrorfusion 프로젝트저품질 자산을 제거하기 위해. 이로 인해 66,062 개의 개체의 정제 풀이 생겼습니다.

새 시스템에 대한 선별 된 데이터 세트 생성에 사용되는 Objaverse 데이터 세트의 예. 출처 : https://arxiv.org/pdf/2212.08051
장면 구조는이 물체를 질감 바닥에 배치하는 것과 관련이있었습니다. CC 텍사스 그리고 HDRI 배경 다색 전체 벽 또는 키가 큰 직사각형 거울을 사용하는 CGI 저장소. 조명은 45도 각도로 물체 위와 뒤에 위치한 면적 광선으로 표준화되었습니다. 물체는 유닛 큐브 내에 맞도록 조정되었으며 미러와 카메라보기의 미리 계산 된 교차점을 사용하여 위치했습니다. Frustums가시성 보장.
Y 축 주위에 무작위 회전이 적용되었으며, ‘부동 아티팩트’를 방지하는 데 사용되는 접지 기술이 사용되었습니다.
보다 복잡한 장면을 시뮬레이션하기 위해 데이터 세트는 ABO 범주를 기반으로 의미 적으로 일관된 페어링에 따라 배열 된 여러 객체를 통합했습니다. 2 차 객체는 겹치는 것을 피하기 위해 배치되어 다양한 폐색과 깊이 관계를 캡처하도록 설계된 3,140 개의 다중 객체 장면을 생성했습니다.

객체 분할 및 깊이 맵 시각화의 삽화와 함께 여러 (2 개 이상) 객체를 포함하는 저자의 데이터 세트에서 렌더링 된 뷰의 예.
훈련 과정
합성 현실주의만으로도 실제 데이터에 대한 강력한 일반화에 불충분하다는 것을 인정하면서 연구원들은 Mirrorfusion 2.0을 훈련하기위한 3 단계 커리큘럼 학습 프로세스를 개발했습니다.
1 단계에서 저자는 무게 안정적인 확산으로 컨디셔닝과 생성 분기의 v1.5 체크 포인트, 단일 객체 훈련에서 모델을 미세 조정했습니다 나뉘다 synmirrorv2 데이터 세트의. 위에서 언급 한 것과는 달리 현실을 반영합니다 프로젝트, 연구원들은 그렇지 않았다 꼭 매달리게 하다 세대 지점. 그런 다음 40,000 회 반복에 대한 모델을 교육했습니다.
2 단계에서,이 모델은 SynmirrorV2의 다중 관수 훈련 분할에 대해 추가로 10,000 개의 반복을 위해 미세 조정되어 시스템에 폐쇄를 처리하도록 가르치고 현실적인 장면에서 발견되는보다 복잡한 공간 배열을 가르칩니다.
마지막으로, 3 단계에서, 추가로 10,000 회복의 반복이 MSD 데이터 세트, MatterPort3d 단안 깊이 추정기.

실제 장면이 깊이 및 세분화 맵으로 분석 된 MSD 데이터 세트의 예제. 출처 : https://arxiv.org/pdf/1908.09101
훈련 중에, 모델이 이용 가능한 깊이 정보 (즉, 마스크 된 접근법)를 최적으로 사용하도록 장려하기 위해 훈련 시간의 20 % 동안 텍스트 프롬프트가 생략되었습니다.
모든 단계에 대해 4 개의 NVIDIA A100 GPU에 대한 교육이 이루어졌습니다 (VRAM 사양은 공급되지 않지만 카드 당 40GB 또는 80GB). 학습 속도 1e-5 아래에서 GPU 당 4의 배치 크기에 사용되었습니다. 아담 최적화.
이 훈련 체계는 강력한 실제 전달성을 개발하려는 의도로 더 단순한 합성 장면으로 시작하여보다 도전적인 구성으로 발전하여 모델에 제시된 작업의 어려움을 점차적으로 증가 시켰습니다.
테스트
저자는 기준선 역할을했던 이전의 최신 ART 인 MirrorFusion에 대해 MirrorFusion 2.0을 평가하고 단일 및 다중 객체 장면을 모두 다루는 MirrorBenchV2 데이터 세트에서 실험을 수행했습니다.
MSD 데이터 세트의 샘플 및 Google 스캔 객체 (GSO) 데이터 세트.
이 평가는 보이지 않는 카테고리에서 2,991 개의 단일 객체 이미지와 ABO의 300 개의 2 객체 장면을 사용했습니다. 성능은 사용하여 측정되었습니다 피크 신호 대 잡음비 (PSNR); 구조적 유사성 지수 (SSIM); 그리고 배운 지각 이미지 패치 유사성 (LPIPS) 점수, 마스크 거울 영역에서의 반사 품질을 평가합니다. 클립 유사성 입력 프롬프트와의 텍스트 정렬을 평가하는 데 사용되었습니다.
정량 테스트에서 저자는 특정 프롬프트를 위해 4 개의 씨앗을 사용하여 이미지를 생성하고 최고의 SSIM 점수로 결과 이미지를 선택했습니다. 정량 테스트에 대한 두 가지보고 결과 표는 다음과 같습니다.

MirrorBenchV2 단일 객체 분할에서 단일 객체 반사 생성 품질에 대한 왼쪽, 정량적 결과. mirrorfusion 2.0은 기준선보다 성능이 우수했으며, 최상의 결과는 굵게 표시되었습니다. 오른쪽, 다중 객체 반사 생성 품질에 대한 정량적 결과 MIRRORBENCHV2 다중 객체 분할. MirrorFusion 2.0 여러 개체로 훈련 된 MirrorFusion 2.0은 버전이 교육없이 훈련 된 버전을 능가했으며 최상의 결과는 굵게 표시되었습니다.
저자는 다음과 같습니다.
‘[The results] 우리의 방법은 기준 방법보다 우수하고 여러 객체에 대한 결제가 복잡한 장면에서 결과를 향상 시킨다는 것을 보여줍니다. ‘
대량의 결과와 저자가 강조한 결과는 질적 테스트에 관한 것입니다. 이 삽화의 차원으로 인해 논문의 예제 만 부분적으로 재현 할 수 있습니다.

MirrorBenchv2에 대한 비교 : 기준선은 정확한 반사 및 공간 일관성을 유지하지 못했고, 의자 방향이 잘못되어 여러 물체의 왜곡 된 반사를 보여주는 반면 (저자는 다수의 반사) mirrorfusion 2.0은 의자와 소파를 정확하게 렌더링하며 정확한 위치, 오리엔테이션 및 구조로 올바르게 렌더링합니다.
이러한 주관적인 결과 중에서, 연구원들은 기준선 모델이 반사에서 객체 방향과 공간 관계를 정확하게 렌더링하지 못했고 종종 잘못된 회전 및 부유 물체와 같은 인공물을 생성한다고 주장합니다. Synmirrorv2에 대해 훈련 된 Mirrorfusion 2.0은 저자들이 경쟁하고 단일 객체 및 다중 객체 장면에서 올바른 객체 방향과 위치를 보존하여보다 현실적이고 일관된 반사를 만듭니다.
아래에서는 앞서 언급 한 GSO 데이터 세트에 대한 질적 결과를 볼 수 있습니다.

GSO 데이터 세트 비교. 기준선은 객체 구조를 허위로 표현하고 불완전하고 왜곡 된 반사를 생성했으며, MirrorFusion 2.0은 제자가 경쟁하고 공간 무결성을 보존하고 분산되지 않은 개체에서도 정확한 지오메트리, 색상 및 세부 사항을 생성합니다.
여기서 저자는 다음과 같습니다.
‘mirrorfusion 2.0은 훨씬 더 정확하고 현실적인 반사를 생성합니다. 예를 들어, 그림 5 (a – 위)에서 mirrorfusion 2.0은 서랍 핸들 (녹색으로 강조)을 올바르게 반영하는 반면, 기준선 모델은 타당한 반사를 생성합니다 (빨간색으로 강조).
마찬가지로, 그림 5 (b)의 “흰색-노란색 머그잔”의 경우, Mirrorfusion 2.0은 기준선과 달리 최소한의 아티팩트가있는 설득력있는 지오메트리를 제공하며, 이는 물체의 지오메트리와 모양을 정확하게 캡처하지 못합니다. ‘
최종 질적 테스트는 앞서 언급 한 실제 MSD 데이터 세트에 대한 것입니다 (아래에 표시된 부분 결과).

MSD 데이터 세트에서 미세 조정 된 Mirrorfusion, Mirrorfusion 2.0 및 Mirrorfusion 2.0을 비교 한 실제 장면 결과. Mirrorfusion 2.0, 저자는 테이블 위의 어수선한 물체와 3 차원 환경 내에서 여러 거울의 존재를 포함하여 복잡한 장면 세부 사항을보다 정확하게 캡처합니다. 원래 논문의 결과의 차원으로 인해 부분적 인 결과 만 표시되며, 전체 결과와 더 나은 해상도를 독자에게 언급합니다.
여기서 저자는 MirrorFusion 2.0이 MirrorBenchV2 및 GSO 데이터에서 잘 수행되었지만 처음에는 MSD 데이터 세트의 복잡한 실제 장면으로 어려움을 겪고 있음을 관찰했습니다. MSD의 서브 세트에서 모델을 미세 조정하면 혼란스러운 환경과 여러 거울을 다루는 능력이 향상되어 Hold-At-At-At-At-At-Ath 테스트 분할에 대한 일관적이고 상세한 반사가 더욱 나타났습니다.
또한, 사용자 연구가 수행되었으며, 여기서 84%의 사용자가 기준선 방법보다 MirrorFusion 2.0에서 선호하는 세대를 가진 것으로보고되었습니다.
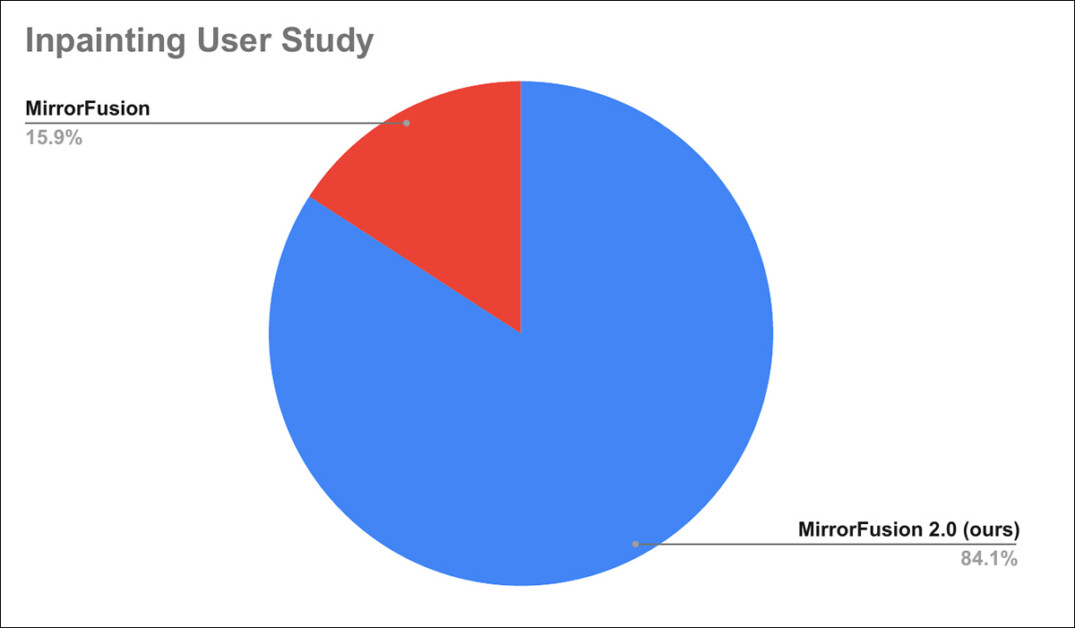
사용자 연구 결과.
사용자 연구에 대한 세부 사항은 논문의 부록으로 강등되었으므로, 우리는 독자에게 연구의 세부 사항에 대해 언급합니다.
결론
논문에 나와있는 몇 가지 결과는 최첨단에서 인상적인 개선이지만,이 특별한 추구의 최첨단은 너무 심각하기 때문에 설득력있는 집계 솔루션조차도 많은 노력으로 이길 수 있습니다. 확산 모델의 기본 아키텍처는 일관된 물리학의 신뢰할 수있는 학습 및 데모에 비해 비대적이므로 문제가 잘못되었으며 분명히 그렇지 않습니다. 우아한 솔루션을 향해 배치됩니다.
또한, 기존 모델에 데이터를 추가하는 것은 이미 LDM 성능의 부족을 해결하는 표준 방법이며, 모든 단점이 앞서 나열되어 있습니다. 미래의 고 규모의 데이터 세트가 반사 관련 데이터 포인트의 분포 (및 주석)에 더 많은주의를 기울여야한다고 가정하는 것이 합리적입니다. 결과 모델 이이 시나리오를 더 잘 처리 할 것으로 예상 할 수 있습니다.
그러나 LDM 출력의 여러 다른 버그 부류에 대해서도 마찬가지입니다. 누가 새로운 논문의 저자가 여기에서 제안하는 솔루션의 종류와 관련된 노력과 돈을 가장 많이 말할 수 있습니까?
2025 년 4 월 28 일 월요일 첫 번째 출판. 4 월 29 일 화요일 : 최종 파라스에서 문법 교정.
게시물 확산 모델의 거울과 반사에 대한 제한된 이해 먼저 나타났습니다 Unite.ai.