{kind=link}


사용자가 다음과 같은 생성 모델을 사용하여 만들고자하는 컨텐츠의 종류 유량 또는 후유아 비디오 컨텐츠 요청이 상당히 일반적인 경우에도 항상 쉽게 사용할 수있는 것은 아니며 생성기가 처리 할 수 있다고 추측 할 수 있습니다.
이 기사에서 볼 수있는 새로운 논문에서 묘사 된 한 예는 점점 더 자존하는 Openai Sora 모델이 프롬프트를 사용하여 해부학 적으로 올바른 파이어 플라이를 렌더링하는 데 어려움이 있다고 지적합니다. ‘Serene Summer Night에 잔디의 잎에 불필요가 빛나고 있습니다.’:

Openai의 Sora는 Firefly Anatomy를 약간 이해하고 있습니다. 출처 : https://arxiv.org/pdf/2503.01739
액면가로 연구 청구를 거의받지 않기 때문에 오늘 SORA에서 동일한 프롬프트를 테스트했으며 약간 더 나은 결과를 얻었습니다. 그러나 Sora는 여전히 생물 발광이 발생하는 Firefly의 꼬리 끝을 밝히지 않고 여전히 빛을 올바르게 렌더링하지 못했습니다.

Sora에서 연구원의 프롬프트에 대한 저의 테스트는 Sora가 Firefly의 빛이 실제로 어디에서 왔는지 이해하지 못하는 결과를 보여줍니다.
아이러니하게도, Adobe Firefly 회사의 저작권 보안 재고 사진 및 비디오에 대해 교육을받은 생성 확산 엔진은 Photoshop의 생성 AI 기능에서 동일한 프롬프트를 시도했을 때 이와 관련하여 1-in-3 성공률 만 관리했습니다.

연구원의 프롬프트의 3 세대가 최종적으로 Adobe Firefly (2025 년 3 월)에서 전혀 빛을 발산하지만 적어도 빛은 곤충 해부학의 올바른 부분에 위치하고 있습니다.
이 예제는 인기있는 기초 모델을 알리는 데 사용되는 교육 세트의 배포, 강조 및 범위가 사용자의 요구와 일치하지 않을 수도 있음을 설명하기 위해 새로운 논문의 연구원들에 의해 강조되었습니다. 사용자가 특별히 도전적인 것을 요구하지 않더라도, Hyperscale 교육 데이터 세트를 가장 효율적이고 성능이 좋은 모델에 적용하는 데 어려움을 겪는 주제입니다.
저자 상태 :
‘[Sora] 잔디와 여름을 성공적으로 생성하면서 빛나는 반딧불의 개념을 포착하지 못합니다. [night]. 데이터 관점에서, 우리는 이것을 주로 추론합니다. [Sora] 잔디밭과 밤에 훈련을받은 반면 Firefly 관련 주제에 대한 교육을받지 못했습니다. 또한 IF [Sora had] 표시된 비디오를 보았습니다 [above image]빛나는 소방관이 어떻게 생겼는지 이해할 것입니다. ‘
그들은 새로 선별 된 데이터 세트를 소개하고 향후 작업에서 방법론을 개선하여 기존 모델보다 사용자 기대에 더 잘 맞는 데이터 컬렉션을 만들 수 있다고 제안합니다.
사람들을위한 데이터
본질적으로 그들의 제안은 다음과 같은 모델 유형에 대한 사용자 정의 데이터 사이에있는 데이터 큐 레이션 접근법을 제시합니다. 로라 (그리고이 접근법은 일반적인 용도로 너무 구체적입니다); 그리고 넓고 비교적 무차별 대량 컬렉션 (예 : Laion 최종 사용 시나리오와 구체적으로 정렬되지 않은 데이터 세트 전원 안정 확산).
방법론과 새로운 데이터 세트로서의 새로운 접근법은 텍스트-비디오에서 사용자의 초점또는 videoufo. Videoufo 데이터 세트는 1291 개의 사용자 중심 주제에 걸쳐 190 만 개의 비디오 클립으로 구성되어 있습니다. 주제 자체는 기존 비디오 데이터 세트에서 정교하게 개발되었으며 다양한 언어 모델 및 자연어 처리 (NLP) 기술을 통해 구문 분석되었습니다.
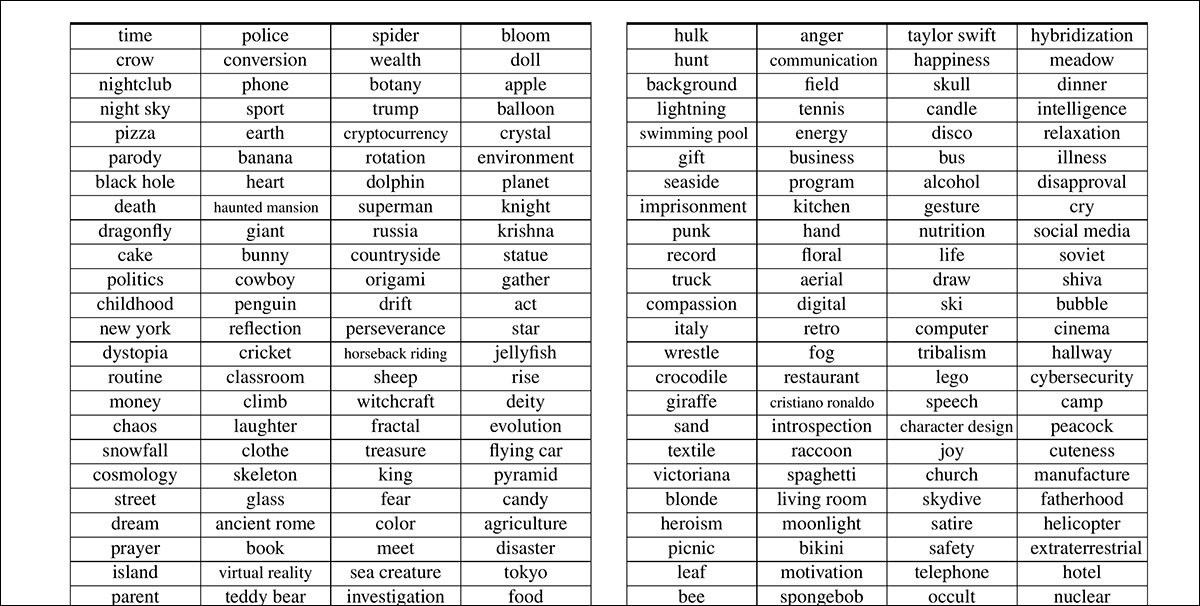
새 논문에 제시된 증류 주제의 샘플.
Videoufo 데이터 세트는 YouTube에서 트롤링 한 많은 소설 비디오를 특징으로합니다. 해당 비디오는 현재 문헌에서 인기있는 비디오 데이터 세트에 포함되어 있지 않으므로 많은 서브 세트에서 큐레이터 된 많은 서브 세트 (그리고 많은 비디오가 논문의 언어를 작성하는 데 실제로 업로드되었습니다).
실제로, 저자들은 그곳이 있다고 주장합니다 기존 비디오 데이터 세트와 0.29% 만 겹칩니다 – 참신한 인상적인 시연.
그에 대한 한 가지 이유는 저자가 사용자가 사용자에게 더 이상 줄을 서서 햄스트링 할 가능성이 적은 크리에이티브 커먼즈 라이센스로 YouTube 비디오 만 수락 할 수 있기 때문일 수 있습니다.이 범주의 비디오는 YouTube 및 기타 대량 플랫폼의 사전 스윕에서 우선 순위가 떨어 졌을 가능성이 있습니다.
둘째, 비디오는 사전 추정 사용자에게 필요한 (위의 이미지 참조)를 기준으로 요청되었으며 무차별 적으로 트롤링되지 않았습니다. 이 두 가지 요소를 조합하여 새로운 컬렉션으로 이어질 수 있습니다. 또한 연구원들은 기존 컬렉션에 소개 된 것들에 대해 기여한 비디오 (예 : 나중에 나올 수있는 비디오)의 YouTube ID를 확인하여 클레임에 대한 신뢰를 빌려주었습니다.
새 논문의 모든 것이 설득력이있는 것은 아니지만, 우리가 여전히 데이터 세트의 고르지 않은 분포의 자비에 처한 정도를 강조하는 흥미로운 읽기는 연구 장면이 종종 데이터 세트 큐 레이션에 직면하는 장애물의 관점에서.
그만큼 새로운 작품 제목이 있습니다 Videoufo : 텍스트-비디오 생성을위한 백만 규모의 사용자 중심 데이터 세트호주의 시드니 대학교 (University of Technology Sydney)와 중국의 잔지안 대학교 (Jhejiang University)에서 각각 두 명의 연구원이 왔습니다.

최종 획득 된 데이터 세트에서 예제를 선택하십시오.
AI 데이터를위한 ‘개인 쇼핑객’
인터넷 이미지와 비디오의 총 합계에 등장하는 주제 및 개념은 반드시 평균 최종 사용자가 생성 시스템에서 요구할 수있는 내용을 반드시 반영하지는 않습니다. 내용과 수요가있는 곳에서도 하다 충돌하는 경향이 있습니다 (포르노와 마찬가지로 풍부하게 사용할 수 있습니다 인터넷에서 큰 관심사 많은 Gen AI 사용자에게), 이것은 새로운 생성 시스템에 대한 개발자의 의도 및 표준에 맞지 않을 수 있습니다.
매일 업로드 된 많은 양의 NSFW 자료 외에도 광고주와 그 자료의 불균형 한 양의 순수량이있을 것입니다. SEO를 조작하려는 시도. 이런 종류의 상업적 자기 이익은 주제의 분포를 공평한 곳에서 멀어지게 만듭니다. 더 나쁜 것은, 의미있는 Hyperscale 데이터에서 개발 된 알고리즘과 모델이 그 자체로 소스 데이터의 경향과 우선 순위를 반영 할 수 있기 때문에 문제에 대처할 수있는 AI 기반 필터링 시스템을 개발하기는 어렵습니다.
따라서 새로운 작품의 저자는 사용자가 원하는 것을 결정하고 이러한 요구에 맞는 비디오를 얻음으로써 제안을 되돌려서 문제에 접근했습니다.
표면적으로,이 접근법은 균형 잡힌 위키 백과 스타일 중립성을 달성하기 위해 의미 론적 경주를 바닥으로 유발할 가능성이있는 것처럼 보입니다. 사용자 수요에 대한 데이터 큐 레이션을 보정하면 가장 낮은 공동체 표지기의 선호도를 증폭시키는 반면 틈새 사용자를 소외시키면서 대부분의 관심사는 필연적으로 더 큰 무게를 가질 것이기 때문입니다.
그럼에도 불구하고, 종이가 어떻게 도전을 해결하는지 살펴 보겠습니다.
재량을 가진 증류 개념
연구원들은 2024 년을 사용했습니다 vidprom 데이터 세트는 나중에 프로젝트의 웹 스케이프를 알리는 주제 분석의 소스입니다.
이 데이터 세트는 저자가 선택되었으며, 이는 공개적으로 공개적으로 사용할 수있는 1m+ 데이터 세트 ‘실제 사용자가 쓴’이기 때문에이 데이터 세트가 새 논문의 두 저자에 의해 자체적으로 큐레이터되었음을 언급해야합니다.
이 논문은*:
‘먼저, 우리는 Vidprom에서 167 백만 개의 프롬프트를 모두 384 차원 벡터를 사용하여 sentencetransformers 다음으로, 우리는이 벡터를 K- 평균으로 클러스터링합니다. 여기서 우리는 클러스터 수를 비교적 큰 값, 즉 2, 000으로 사전 설정하고 다음 단계에서 유사한 클러스터를 병합합니다.
‘마지막으로, 각 클러스터마다 우리는 묻습니다 GPT-4O 주제를 마치려면 [one or two words]. ‘
저자는 특정 개념이 뚜렷하지만 특히 인접한 것으로 지적합니다. 교회 그리고 성당. 이런 종류의 경우에 대한 기준은 너무 세분화되어있어 용어 대신 각각의 개 품종에 대한 개념 임베딩 (예 : 개; 너무 광범위한 기준은 과도한 수의 하위 개념을 단일 과밀 한 개념에 상관시킬 수 있습니다. 따라서이 논문은 그러한 경우를 평가하는 데 필요한 균형 행위에 주목합니다.
단수 및 복수형 형태가 병합되었고 동사는 기본 (부정사) 형태로 복원되었습니다. 과도하게 광범위한 용어 – 생기,,, 장면,,, 영화 그리고 움직임 – 제거되었습니다.
따라서 1,291 개의 주제가 얻어졌습니다 (전체 목록은 소스 용지의 보충 섹션에서 사용할 수 있음).
웹 스craping을 선택하십시오
다음으로, 연구원들은 공식 YouTube API를 사용하여 2024 데이터 세트에서 증류 된 기준에 따라 비디오를 찾아 각 주제에 대해 500 개의 비디오를 얻었습니다. 필수 크리에이티브 커먼즈 라이센스 외에도 각 비디오의 해상도는 720p 이상이어야했으며 4 분보다 짧아야했습니다.
이런 식으로 586,490 개의 비디오가 YouTube에서 긁 혔습니다.
저자는 다운로드 된 비디오의 YouTube ID를 여러 가지 인기있는 데이터 세트와 비교했습니다. OpenVID-1M; HD-vila-100m; 내부; 코알라 -36m; LVD-2M; 미라 다다; 팬더 -70m; vidgen-1m; 그리고 webvid-10m.
그들은이 오래된 컬렉션에 등장한 Videoufo 클립의 1,675 ID (위에서 언급 한 0.29%) 만 발견했으며, 데이터 세트 비교 목록이 철저하지는 않지만 생성 비디오 장면에서 가장 크고 영향력있는 플레이어를 모두 포함한다는 것을 인정해야합니다.
분할 및 평가
위에서 언급 한 Panda-70m 논문에 요약 된 방법론에 따르면, 얻은 비디오는 이후 다중 클립으로 분할되었다. 샷 경계는 추정되었고, 어셈블리는 스티치되었으며, 연결된 비디오는 단일 클립으로 나뉘어졌으며, 간단하고 상세한 캡션이 제공되었습니다.

VideOUFO 데이터 세트의 각 데이터 항목에는 클립, ID, 시작 및 종료 시간 및 간단하고 자세한 캡션이 있습니다.
간단한 캡션은 Panda-70m 방법과 자세한 비디오 캡션에 의해 처리되었습니다. QWEN2-VL-7B설립 된 지침에 따라 오픈-소라 플랜. 클립이 의도 된 대상 개념을 성공적으로 구현하지 않은 경우, 각각의 클립에 대한 자세한 캡션은 주제에 진정으로 적합한 지 확인하기 위해 GPT-4O MINI에 공급되었습니다. 저자는 GPT-4O를 통해 평가를 선호했지만 이것은 수백만 개의 비디오 클립에 비해 너무 비쌌을 것입니다.
비디오 품질 평가는 6 가지 방법으로 처리되었습니다. vbench 프로젝트 .
비교
저자는 위에서 언급 한 이전 데이터 세트에서 주제 추출 프로세스를 반복했습니다. 이를 위해서는 다른 컬렉션에서 불가피하게 다른 범주에 파생 된 범주의 Videoufo 범주를 의미 적으로 일치시켜야했습니다. 그러한 프로세스는 근사치 동등한 범주 만 공급한다는 것을 인정해야하므로 이는 경험적 비교를 보증하기위한 프로세스가 너무 주관적 일 수 있습니다.
그럼에도 불구하고, 아래 이미지에서 우리는이 방법에 의해 얻은 연구자들이 다음과 같은 결과를 봅니다.
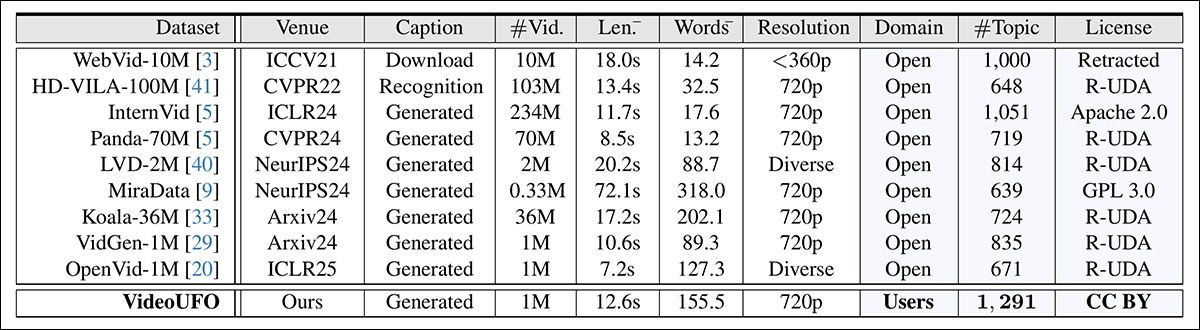
Videoufo 및 이전 데이터 세트에서 파생 된 기본 속성의 비교.
연구원들은 그들의 분석이 각 데이터 세트에 제공된 기존 캡션 및 설명에 의존했음을 인정합니다. 그들은 videoufo와 동일한 방법을 사용하여 이전 데이터 세트를 재 캡션하는 것이보다 직접적인 비교를 제공 할 수 있음을 인정합니다. 그러나 엄청난 양의 데이터 포인트를 감안할 때,이 접근법이 엄청나게 비싸다는 결론은 정당화 된 것 같습니다.
세대
저자는 사용자 중심의 개념에 대한 텍스트-비디오 모델의 성능을 평가하기위한 벤치 마크를 개발했습니다. Benchufo. 이것은 videoufo의 1,291 개의 증류 된 사용자 주제 중에서 791 명을 선택해야했습니다. 선택된 각 주제에 대해 VidProm의 10 개의 텍스트 프롬프트가 무작위로 선택되었습니다.
각 프롬프트는 텍스트-비디오 모델로 전달되었으며, 위에서 언급 한 QWEN2-VL-7B 캡션자는 생성 된 결과를 평가하는 데 사용됩니다. 따라서 생성 된 모든 비디오가 캡션되면, SentencetRansformers는 각 경우 입력 프롬프트 및 출력 (추론) 설명 둘 다에 대한 코사인 유사성을 계산하는 데 사용되었습니다.
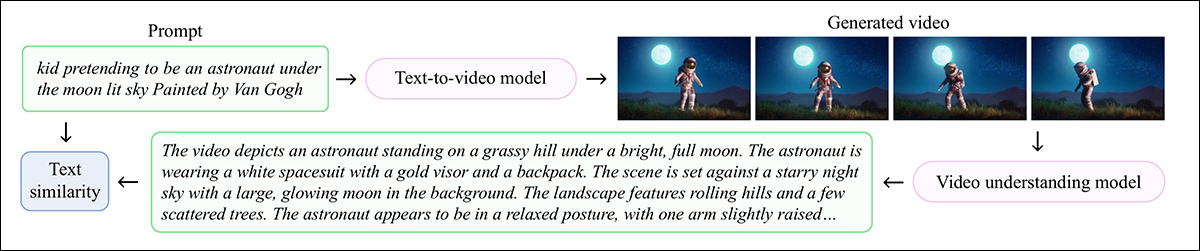
Benchufo 프로세스를위한 스키마.
평가 된 생성 모델은 다음과 같습니다. 미라; 쇼 -1; LTX- 비디오; 오픈-소라 플랜; 오픈 소라; TF-T2V; Mochi-1; 높은; 피카; Repvideo; T2V-Zero; Cogvideox; 라떼 -1; 후유아 비디오; 라비; 그리고 피라미드.
videoufo 외에 mvdit-vidgen 그리고 MVDIT-OPENVID 대체 교육 데이터 세트였습니다.
결과는 아키텍처 및 데이터 세트에서 10 ~ 50 번째 최악의 성과 및 가장 성능이 좋은 주제를 고려합니다.
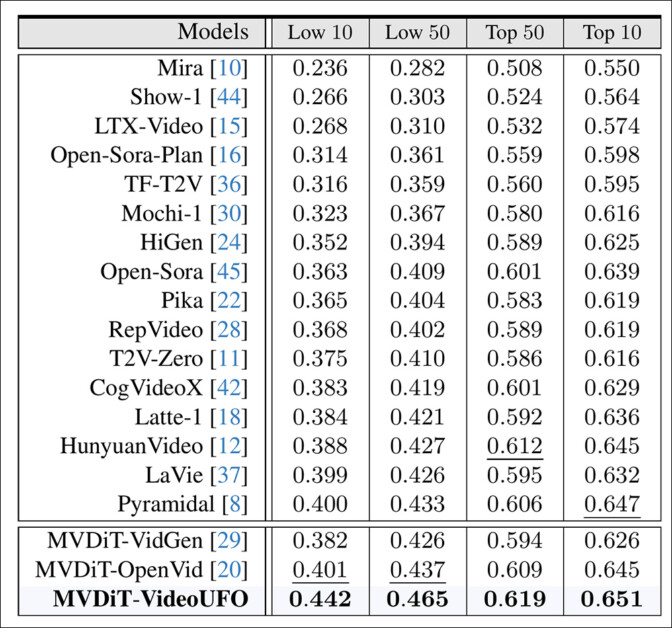
Benchufo에서 공개 T2V 모델 대 저자의 숙련 된 모델의 성능에 대한 결과.
여기서 저자는 다음과 같습니다.
‘현재 텍스트-비디오 모델은 모든 사용자 중심의 주제에서 일관되게 성능을 발휘하지 않습니다. 구체적으로, 상위 10 주와 100 주제 사이에 0.233에서 0.314 범위의 점수 차이가 있습니다. 이 모델들은 그러한 비디오에 대한 훈련이 충분하지 않아서“거대한 오징어”,“동물 세포”,“반 고그”및“고대 이집트인”과 같은 주제를 효과적으로 이해하지 못할 수 있습니다.
‘현재 텍스트-비디오 모델은 가장 성능이 좋은 주제에서 어느 정도의 일관성을 보여줍니다. 우리는 대부분의 텍스트-비디오 모델이 ‘Seagull’, ‘Panda’, ‘Dolphin’, ‘Camel’및 ‘Owl’과 같은 동물 관련 주제에 대한 비디오를 생성하는 데 탁월하다는 것을 알게됩니다. 우리는 이것이 현재 비디오 데이터 세트에서 동물에 대한 편견 때문이라고 추론합니다. ‘
결론
Videoufo는 새로운 데이터의 관점에서만 뛰어난 제품입니다. YouTube ID를 평가하고 제거하는 데 오류가없고 데이터 세트에 연구 장면에 새로운 자료가 너무 많으면 드물고 잠재적으로 귀중한 제안입니다.
단점은 핵심 방법론에 신뢰를 주어야한다는 것입니다. 사용자 요구가 웹 스크래핑 공식에 알릴 것이라고 생각하지 않으면 고유 한 문제의 편견과 함께 제공되는 데이터 세트에 구매할 것입니다.
또한, 증류 된 주제의 유용성은 사용 된 증류 방법의 신뢰성 (일반적으로 예산 제약에 의해 방해 함)과 소스 자료를 제공하는 2024 데이터 세트에 대한 공식 방법에 따라 달라집니다.
즉, videoufo는 확실히 추가 조사를 할 가치가 있습니다. Hugging Face에서 사용할 수 있습니다.
* 하이퍼 링크에 대한 저자의 인용을 대체합니다.
2025 년 3 월 5 일 수요일에 처음 출판되었습니다
게시물 사용자 중심 데이터로 비디오 AI 교육을 다시 생각합니다 먼저 나타났습니다 Unite.ai.