



대규모 언어 모델(LLM)을 인간의 가치와 선호도에 맞추는 것은 어렵습니다. 다음과 같은 기존 방법 인간 피드백을 통한 강화 학습 (RLHF)는 인간 입력을 통합하여 모델 출력을 개선함으로써 길을 열었습니다. 그러나 RLHF는 복잡하고 리소스 집약적일 수 있으며 상당한 계산 능력과 데이터 처리가 필요합니다. 직접 선호도 최적화 (DPO)는 새롭고 간소화된 접근 방식으로 등장하여 이러한 기존 방식에 대한 효율적인 대안을 제공합니다. DPO는 최적화 프로세스를 단순화하여 계산 부담을 줄일 뿐만 아니라 모델이 인간의 선호도에 빠르게 적응하는 능력을 향상시킵니다.
이 가이드에서는 DPO에 대해 자세히 알아보고, 그 기반, 구현 및 실제 응용 프로그램을 살펴보겠습니다.
선호도 정렬의 필요성
DPO를 파헤치기 전에 LLM을 인간의 선호도에 맞추는 것이 왜 그렇게 중요한지 이해하는 것이 중요합니다. 인상적인 역량에도 불구하고 방대한 데이터 세트로 훈련된 LLM은 때때로 일관성이 없거나 편향적이거나 인간의 가치와 맞지 않는 출력을 생성할 수 있습니다. 이러한 불일치는 다양한 방식으로 나타날 수 있습니다.
- 안전하지 않거나 유해한 콘텐츠 생성
- 부정확하거나 오해의 소지가 있는 정보 제공
- 훈련 데이터에 존재하는 편향을 나타냄
이러한 문제를 해결하기 위해 연구자들은 인간의 피드백을 사용하여 LLM을 미세 조정하는 기술을 개발했습니다. 이러한 접근 방식 중 가장 두드러진 것은 RLHF였습니다.
RLHF 이해: DPO의 선구자
인간 피드백을 통한 강화 학습(RLHF)은 LLM을 인간의 선호도에 맞추는 데 가장 많이 쓰이는 방법이었습니다. RLHF 프로세스를 분석하여 복잡성을 이해해 보겠습니다.
에이) 감독된 미세 조정(SFT): 프로세스는 고품질 응답 데이터 세트에서 사전 훈련된 LLM을 미세 조정하는 것으로 시작됩니다. 이 단계는 모델이 대상 작업에 대해 더욱 관련성 있고 일관된 출력을 생성하는 데 도움이 됩니다.
비) 보상 모델링: 별도의 보상 모델은 인간의 선호도를 예측하도록 훈련됩니다. 여기에는 다음이 포함됩니다.
- 주어진 프롬프트에 대한 응답 쌍 생성
- 인간이 선호하는 응답을 평가하도록 함
- 이러한 선호도를 예측하기 위한 모델 학습
기음) 강화 학습: 미세 조정된 LLM은 강화 학습을 사용하여 더욱 최적화됩니다. 보상 모델은 피드백을 제공하여 LLM이 인간의 선호도에 맞는 응답을 생성하도록 안내합니다.
다음은 RLHF 프로세스를 설명하기 위한 단순화된 Python 의사코드입니다.
RLHF는 효과적이기는 하지만 몇 가지 단점이 있습니다.
- 여러 모델(SFT, 보상 모델, RL 최적화 모델)의 훈련과 유지 관리가 필요합니다.
- RL 프로세스는 불안정할 수 있으며 하이퍼 매개변수에 민감할 수 있습니다.
- 모델을 통한 많은 전후 패스가 필요하므로 계산 비용이 많이 듭니다.
이러한 한계로 인해 더 간단하고 효율적인 대안을 모색하는 과정이 추진되었고, 그 결과 DPO가 개발되었습니다.
직접 선호도 최적화: 핵심 개념

직접 선호도 최적화 https://arxiv.org/abs/2305.18290
이 이미지는 LLM 출력을 인간의 선호도에 맞추는 두 가지 뚜렷한 접근 방식을 대조합니다. 인간 피드백을 통한 강화 학습(RLHF)과 직접 선호도 최적화(DPO). RLHF는 보상 모델을 사용하여 반복적 피드백 루프를 통해 언어 모델의 정책을 안내하는 반면, DPO는 선호도 데이터를 사용하여 모델 출력을 인간이 선호하는 응답과 일치하도록 직접 최적화합니다. 이 비교는 각 방법의 강점과 잠재적인 적용 분야를 강조하여 미래의 LLM이 인간의 기대에 더 잘 부합하도록 훈련될 수 있는 방법에 대한 통찰력을 제공합니다.
DPO의 핵심 아이디어:
에이) 암묵적 보상 모델링: DPO는 언어 모델 자체를 암묵적인 보상 함수로 처리하여 별도의 보상 모델의 필요성을 제거합니다.
비) 정책 기반 공식화: 보상 함수를 최적화하는 대신 DPO는 정책(언어 모델)을 직접 최적화하여 선호하는 응답의 확률을 최대화합니다.
기음) 폐쇄형 솔루션: DPO는 최적 정책에 대한 폐쇄형 솔루션을 제공하는 수학적 통찰력을 활용하여 반복적인 RL 업데이트가 필요 없습니다.
DPO 구현: 실용적인 코드 연습
아래 이미지는 PyTorch를 사용하여 DPO 손실 함수를 구현하는 코드 조각을 보여줍니다. 이 함수는 언어 모델이 인간의 선호도에 따라 출력을 우선시하는 방식을 개선하는 데 중요한 역할을 합니다. 다음은 주요 구성 요소에 대한 세부 정보입니다.
- 함수 서명: 그
dpo_loss이 함수는 정책 로그 확률을 포함한 여러 매개변수를 사용합니다.pi_logps), 참조 모델 로그 확률(ref_logps), 그리고 선호되는 완성 및 선호되지 않는 완성을 나타내는 지수(yw_idxs,yl_idxs). 또한,beta매개변수는 KL 페널티의 강도를 제어합니다. - 로그 확률 추출: 이 코드는 정책 모델과 참조 모델 모두에서 선호되는 완료와 선호되지 않는 완료에 대한 로그 확률을 추출합니다.
- 로그 비율 계산: 선호되는 완료와 선호되지 않는 완료에 대한 로그 확률의 차이는 정책 모델과 참조 모델 모두에 대해 계산됩니다. 이 비율은 최적화의 방향과 규모를 결정하는 데 중요합니다.
- 손실 및 보상 계산: 손실은 다음을 사용하여 계산됩니다.
logsigmoid기능은 정책과 참조 로그 확률의 차이를 조정하여 보상이 결정됩니다.beta.

PyTorch를 사용한 DPO 손실 함수
이러한 목표를 어떻게 달성하는지 이해하기 위해 DPO의 수학을 깊이 살펴보겠습니다.
DPO의 수학
DPO는 선호도 학습 문제를 영리하게 재구성한 것입니다. 단계별 분석은 다음과 같습니다.
a) 시작점: KL 제약 보상 극대화
원래 RLHF 목표는 다음과 같이 표현될 수 있습니다.
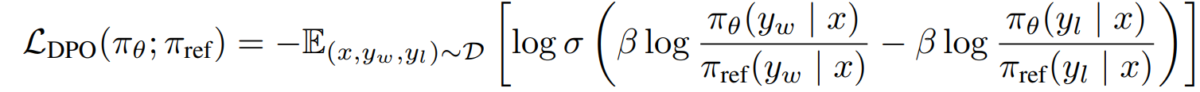
- πθ는 우리가 최적화하고 있는 정책(언어 모델)입니다.
- r(x,y)는 보상 함수입니다.
- πref는 참조 정책(일반적으로 초기 SFT 모델)입니다.
- β는 KL 발산 제약의 강도를 제어합니다.
비) 최적의 정책 양식: 이 목표에 대한 최적의 정책은 다음과 같은 형태를 갖는다는 것을 보여줄 수 있습니다.
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))여기서 Z(x)는 정규화 상수입니다.
기음) 보상 정책의 이중성: DPO의 핵심 통찰력은 최적 정책의 관점에서 보상 기능을 표현하는 것입니다.
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) 선호도 모델 선호도가 Bradley-Terry 모델을 따른다고 가정하면 y1을 y2보다 선호할 확률을 다음과 같이 표현할 수 있습니다.
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))여기서 σ는 로지스틱 함수입니다.
이자형) DPO 목표 보상 정책 이중성을 선호도 모델에 대입하면 다음과 같은 DPO 목표에 도달합니다.
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]이 목표는 RL 알고리즘을 사용하지 않고도 표준 경사 하강 기술을 사용하여 최적화할 수 있습니다.
DPO 구현
이제 DPO의 이론을 이해했으므로 실제로 구현하는 방법을 살펴보겠습니다. 파이썬 그리고 파이토치 이 예의 경우:
import torchimport torch.nn.functional as Fclass DPOTrainer: def __init__(self, model, ref_model, beta=0.1, lr=1e-5): self.model = model self.ref_model = ref_model self.beta = beta self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr) def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): """ pi_logps: policy logprobs, shape (B,) ref_logps: reference model logprobs, shape (B,) yw_idxs: preferred completion indices in [0, B-1], shape (T,) yl_idxs: dispreferred completion indices in [0, B-1], shape (T,) beta: temperature controlling strength of KL penalty Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair. """ # Extract log probabilities for the preferred and dispreferred completions pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs] # Calculate log-ratios pi_logratios = pi_yw_logps - pi_yl_logps ref_logratios = ref_yw_logps - ref_yl_logps # Compute DPO loss losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios)) rewards = self.beta * (pi_logps - ref_logps).detach() return losses.mean(), rewards def train_step(self, batch): x, yw_idxs, yl_idxs = batch self.optimizer.zero_grad() # Compute log probabilities for the model and the reference model pi_logps = self.model(x).log_softmax(-1) ref_logps = self.ref_model(x).log_softmax(-1) # Compute the loss loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs) loss.backward() self.optimizer.step() return loss.item()# Usagemodel = YourLanguageModel() # Initialize your modelref_model = YourLanguageModel() # Load pre-trained reference modeltrainer = DPOTrainer(model, ref_model)for batch in dataloader: loss = trainer.train_step(batch) print(f"Loss: {loss}")
도전과 미래 방향
DPO는 기존 RLHF 접근 방식에 비해 상당한 이점을 제공하지만 여전히 과제와 추가 연구가 필요한 분야가 있습니다.
a) 더 큰 모델로의 확장성:
언어 모델의 크기가 계속 커지면서, 수천억 개의 매개변수가 있는 모델에 DPO를 효율적으로 적용하는 것은 여전히 열린 과제로 남아 있습니다. 연구자들은 다음과 같은 기술을 탐구하고 있습니다.
- 효율적인 미세 조정 방법(예: LoRA, 접두사 조정)
- 분산된 훈련 최적화
- 그래디언트 체크포인팅 및 혼합 정밀도 학습
DPO와 함께 LoRA를 사용하는 예:
from peft import LoraConfig, get_peft_modelclass DPOTrainerWithLoRA(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8): lora_config = LoraConfig( r=lora_rank, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) self.model = get_peft_model(model, lora_config) self.ref_model = ref_model self.beta = beta self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)# Usagebase_model = YourLargeLanguageModel()dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) 멀티태스크 및 소수 샷 적응:
선호도 데이터가 제한적인 새로운 작업이나 도메인에 효율적으로 적응할 수 있는 DPO 기술을 개발하는 것은 활발한 연구 분야입니다. 탐구 중인 접근 방식은 다음과 같습니다.
- 빠른 적응을 위한 메타 학습 프레임워크
- DPO를 위한 프롬프트 기반 미세 조정
- 일반 선호도 모델에서 특정 도메인으로 학습을 전환합니다.
c) 모호하거나 상충되는 선호도 처리:
실제 선호도 데이터에는 종종 모호성이나 갈등이 포함됩니다. 이러한 데이터에 대한 DPO의 견고성을 개선하는 것이 중요합니다. 잠재적인 해결책은 다음과 같습니다.
- 확률적 선호도 모델링
- 모호성을 해결하기 위한 능동 학습
- 다중 에이전트 선호도 집계
확률적 선호도 모델링의 예:
class ProbabilisticDPOTrainer(DPOTrainer): def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob): # Compute log ratios pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs] log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1) loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) + (1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff)) return loss.mean()# Usagetrainer = ProbabilisticDPOTrainer(model, ref_model)loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) DPO를 다른 정렬 기술과 결합:
DPO를 다른 정렬 접근 방식과 통합하면 보다 견고하고 유능한 시스템을 구축할 수 있습니다.
- 명시적 제약 조건 만족을 위한 헌법적 AI 원칙
- 복잡한 선호도 유도를 위한 토론 및 재귀적 보상 모델링
- 기본 보상 함수를 추론하기 위한 역 강화 학습
DPO와 헌법 AI를 결합하는 예:
class ConstitutionalDPOTrainer(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None): super().__init__(model, ref_model, beta, lr) self.constraints = constraints or [] def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs) constraint_loss = 0 for constraint in self.constraints: constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs) return base_loss + constraint_loss# Usagedef safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs): # Implement safety checking logic unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps) return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5constraints = [safety_constraint]trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
실용적 고려 사항 및 모범 사례
실제 애플리케이션에 DPO를 구현할 때 다음 팁을 고려하세요.
에이) 데이터 품질: 선호도 데이터의 품질은 매우 중요합니다. 데이터 세트가 다음 사항을 충족하는지 확인하세요.
- 다양한 범위의 입력과 원하는 동작을 포괄합니다.
- 일관되고 안정적인 기본 설정 주석이 있습니다
- 다양한 유형의 선호도(예: 사실성, 안전성, 스타일)를 균형 있게 조절합니다.
비) 하이퍼파라미터 튜닝: DPO는 RLHF보다 하이퍼파라미터가 적지만 튜닝은 여전히 중요합니다.
- β(베타): 선호도 만족과 참조 모델과의 차이 간의 균형을 제어합니다. 다음 값부터 시작합니다. 0.1-0.5.
- 학습률: 일반적으로 표준 미세 조정보다 낮은 학습률을 사용합니다. 1e-6에서 1e-5까지.
- 배치 크기: 더 큰 배치 크기(32-128)은 선호도 학습에 효과적인 경우가 많습니다.
기음) 반복적 개선: DPO는 반복적으로 적용될 수 있습니다.
- DPO를 사용하여 초기 모델 학습
- 훈련된 모델을 사용하여 새로운 응답 생성
- 이러한 응답에 대한 새로운 선호도 데이터 수집
- 확장된 데이터 세트를 사용하여 재교육

직접 선호도 최적화 성능
이 이미지는 Direct Preference Optimization(DPO), Supervised Fine-Tuning(SFT), Proximal Policy Optimization(PPO)을 포함한 다양한 훈련 기법에서 인간의 판단과 비교한 GPT-4와 같은 LLM의 성능을 자세히 살펴봅니다. 이 표는 GPT-4의 출력이 특히 요약 작업에서 인간의 선호도와 점점 더 일치하고 있음을 보여줍니다. GPT-4와 인간 검토자 간의 합의 수준은 이 모델이 인간이 생성한 콘텐츠와 거의 마찬가지로 인간 평가자에게 공감을 얻는 콘텐츠를 생성할 수 있는 능력을 보여줍니다.
사례 연구 및 응용 프로그램
DPO의 효과를 설명하기 위해 몇 가지 실제 응용 프로그램과 몇 가지 변형을 살펴보겠습니다.
- 반복적 DPO: Snorkel(2023)이 개발한 이 변형은 거부 샘플링과 DPO를 결합하여 훈련 데이터에 대한 보다 정교한 선택 프로세스를 가능하게 합니다. 선호도 샘플링의 여러 라운드를 반복함으로써 모델은 노이즈가 있거나 편향된 선호도에 대한 과적합을 일반화하고 피할 수 있습니다.
- 기업공개(IPO)반복적 선호도 최적화): Azar et al. (2023)이 도입한 IPO는 선호도 기반 최적화에서 흔히 발생하는 문제인 과적합을 방지하기 위해 정규화 항목을 추가합니다. xtension을 사용하면 모델이 기본 설정을 준수하는 것과 일반화 기능을 유지하는 것 사이의 균형을 유지할 수 있습니다.
- WHO (지식 전달 최적화): Ethayarajh et al. (2023)의 최근 변형인 KTO는 이진 선호도를 완전히 없앱니다. 대신 참조 모델에서 정책 모델로 지식을 이전하는 데 집중하여 인간의 가치와 더 매끄럽고 일관된 정렬을 최적화합니다.
- 크로스 도메인 학습을 위한 멀티 모달 DPO Xu et al. (2024)에 의해: DPO가 텍스트, 이미지, 오디오 등 다양한 모달리티에 적용되는 접근 방식으로, 다양한 데이터 유형에서 모델을 인간의 선호도에 맞춰 정렬하는 데 있어 다재다능함을 보여줍니다. 이 연구는 복잡하고 다중 모달 작업을 처리할 수 있는 보다 포괄적인 AI 시스템을 만드는 데 있어 DPO의 잠재력을 강조합니다.