



LG AI Research의 최근 논문에 따르면 AI 모델을 훈련시키는 데 사용되는 ‘개방형’데이터 세트가 잘못된 보안 감각을 제공 할 수 있습니다. ‘상업적으로 유용한’것으로 표시된 5 개의 AI 데이터 세트 중 거의 4 개가 실제로 숨겨진 법적 위험이 포함되어 있음을 발견했습니다.
이러한 위험은 공개되지 않은 저작권이없는 자료 포함부터 데이터 세트 의존성에 깊이 묻힌 제한 라이센스 용어에 이르기까지 다양합니다. 논문의 결과가 정확한 경우, 공개 데이터 세트에 의존하는 회사는 현재 AI 파이프 라인을 재고하거나 법적 노출을 하류로 위험에 빠뜨려 야 할 수 있습니다.
연구원들은 급진적 인 것을 제안합니다 잠재적으로 논란의 여지가 있습니다 솔루션 : 데이터 세트 이력을 스캔하고 감사 할 수있는 AI 기반 규정 준수 에이전트는 인간 변호사보다 빠르고 정확합니다.
논문은 다음과 같습니다.
‘이 논문은 AI 교육 데이터 세트의 법적 위험을 표면 수준의 라이센스 용어를 검토하여 결정할 수 없다고 주장합니다. 데이터 세트 재분배에 대한 철저한 엔드 투 엔드 분석은 준수를 보장하기 위해 필수적입니다.
‘이러한 분석은 복잡성과 규모로 인해 인간 능력을 넘어서기 때문에 AI 에이전트는 더 빠른 속도와 정확성 으로이 격차를 해소 할 수 있습니다. 자동화가 없으면 중요한 법적 위험은 윤리적 AI 개발 및 규제 준수를 위태롭게 유지하고 있습니다.
‘우리는 AI 연구 커뮤니티가 엔드 투 엔드 법률 분석을 기본 요구 사항으로 인식하고 AI 중심 접근 방식을 확장 가능한 데이터 세트 규정 준수에 대한 실행 가능한 경로로 채택 할 것을 촉구합니다.’
연구원의 자동화 시스템은 개별 라이센스를 기반으로 상업적으로 사용할 수있는 2,852 개의 인기있는 데이터 세트를 검토 한 결과, 연구원의 자동 시스템은 모든 구성 요소와 종속성이 추적되면 605 명 (약 21%)만이 상용화에 합법적으로 안전하다는 것을 발견했습니다.
그만큼 새로운 종이 제목이 있습니다 귀하가 보는 라이센스를 신뢰하지 마십시오-데이터 세트 규정 준수는 대규모 규모의 AI 기반 수명주기 추적이 필요합니다.LG AI Research의 8 명의 연구원에서 나왔습니다.
권리와 잘못
저자가 강조합니다 도전 데이터 세트 교육에 대한 이전의 학문적 ‘공정한 사용’사고 방식이 법적 보호가 불분명하고 안전한 항구가 더 이상 보장되지 않는 골절 된 환경에 대한 방법을 제공하기 때문에 점점 더 불확실한 법적 환경에서 AI 개발을 추진하는 기업들이 직면하게됩니다.
하나의 출판물로 지적했다 최근에 기업들은 교육 데이터의 출처에 대해 점점 더 방어되고 있습니다. 저자 Adam Buick 의견*:
‘[While] OpenAi는 GPT-3의 주요 데이터 소스를 공개했으며, GPT-4를 소개합니다. 노출된 모델이 교육을받은 데이터는 ‘공개적으로 이용 가능한 데이터 (예 : 인터넷 데이터)와 타사 공급자의 라이센스가 부여 된 데이터’의 혼합이었다.
‘이 투명성에서 벗어난 동기는 AI 개발자들에 의해 특정한 세부 사항으로 표현되지 않았으며, 많은 경우에 전혀 설명하지 않았다.
‘OpenAi는’경쟁 환경과 대규모 모델의 안전 영향 ‘에 대한 우려에 근거하여 GPT-4에 대한 자세한 내용을 발표하지 않기로 한 결정을 정당화했다.
투명성은 불쾌한 용어 일 수 있습니다. 예를 들어, Adobe의 주력 파이어 플라이 Adobe가 악용 할 권리가있는 재고 데이터에 대해 교육을받은 생성 모델은 아마도 고객이 시스템 사용의 합법성에 대한 재확인을 제공했을 것입니다. 나중에 일부 증거가 나타났습니다 Firefly Data Pot은 다른 플랫폼의 잠재적으로 저작권이있는 데이터로 ‘강화’되었습니다.
우리처럼 이번 주 초에 논의되었습니다유연한 Creative Commons 라이센스로 YouTube 동영상을 긁어 낼 수있는 데이터 세트에서 라이센스 준수를 보장하기 위해 설계된 이니셔티브가 증가하고 있습니다.
문제는 새로운 연구에서 알 수 있듯이 라이센스 자체가 잘못되거나 잘못되었을 수 있다는 것입니다.
오픈 소스 데이터 세트 검사
컨텍스트가 지속적으로 변화 할 때 저자의 넥서스와 같은 평가 시스템을 개발하기는 어렵습니다. 따라서이 논문은 Nexus Data Compliance Framework 시스템이 ‘이 시점의 다양한 선례와 법적 근거’를 기반으로한다고 명시하고 있습니다.
Nexus는 호출 된 AI 구동 에이전트를 사용합니다 자가 준수 자동화 된 데이터 준수. 자동 준수는 세 가지 주요 모듈로 구성됩니다 : 웹 탐색을위한 탐색 모듈; 정보 추출을위한 질문 응답 (QA) 모듈; 법적 위험 평가를위한 스코어링 모듈.

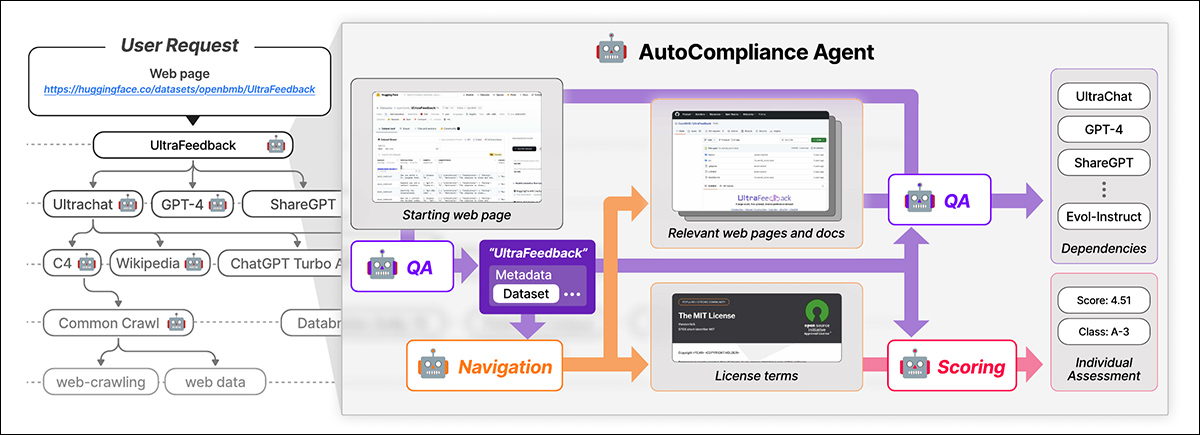
자동 준수는 사용자가 제공하는 웹 페이지로 시작합니다. AI는 주요 세부 사항을 추출하고 관련 리소스 검색, 라이센스 용어 및 종속성을 식별하고 법적 위험 점수를 지정합니다.. 출처 : https://arxiv.org/pdf/2503.02784
이 모듈은 Exaone-3.5-32B-비축 합성 및 인간-표지 된 데이터에 대한 교육을받은 모델. AutoCalliance는 또한 효율성을 높이기 위해 캐싱 결과를 캐싱하기 위해 데이터베이스를 사용합니다.
자동 준수는 사용자가 제공하는 데이터 세트 URL로 시작하여 루트 엔티티로 취급하여 라이센스 용어 및 종속성을 검색하며 링크 된 데이터 세트를 재귀 적으로 추적하여 라이센스 종속성 그래프를 구축합니다. 모든 연결이 매핑되면 규정 준수 점수를 계산하고 위험 분류를 할당합니다.
새로운 작업에 요약 된 데이터 규정 준수 프레임 워크는 다양한 것을 식별합니다.† 데이터 수명주기에 관련된 엔티티 유형 데이터 세트AI 훈련을위한 핵심 입력을 형성하는; 데이터 처리 소프트웨어 및 AI 모델데이터를 변환하고 활용하는 데 사용됩니다. 그리고 플랫폼 서비스 제공 업체데이터 처리를 용이하게하는.
이 시스템은 AI 개발과 관련된 구성 요소의 광범위한 생태계를 포함하여 데이터 세트 라이센스의 ROTE 평가를 넘어서 이러한 다양한 엔티티 및 상호 의존성을 고려하여 법적 위험을 전체적으로 평가합니다.

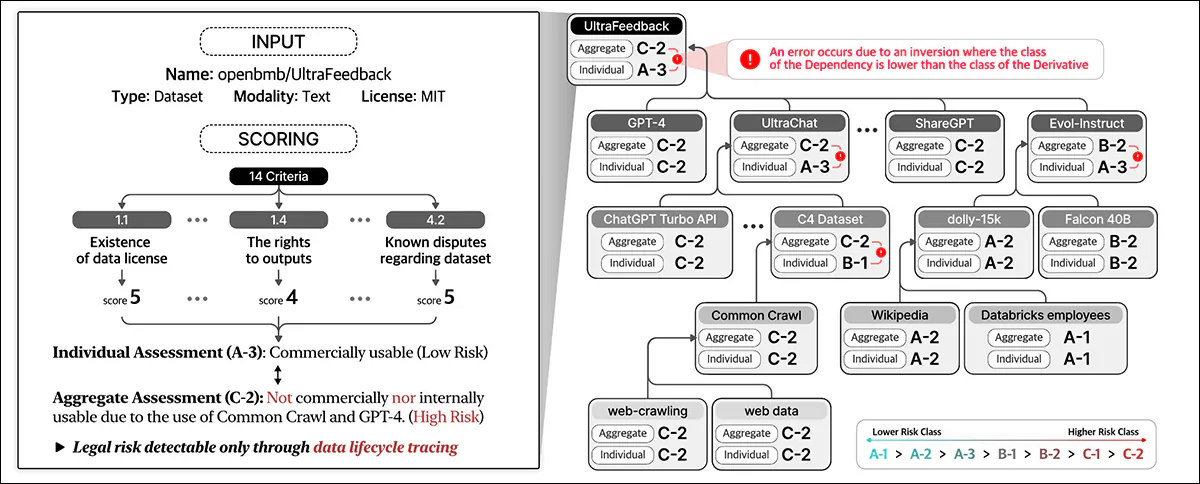
데이터 준수는 전체 데이터 라이프 사이클에서 법적 위험을 평가합니다. 데이터 세트 세부 사항과 14 개의 기준을 기반으로 점수를 할당하여 개별 엔티티를 분류하고 종속성에 걸쳐 위험을 집계합니다.
훈련 및 지표
저자는 Hugging Face에서 상위 1,000 개의 가장 다운로드 된 데이터 세트의 URL을 추출하여 216 개 항목을 무작위로 샘플링하여 테스트 세트를 구성했습니다.
Exaone 모델은있었습니다 미세 조정 저자의 사용자 정의 데이터 세트에서 내비게이션 모듈 및 질문 응답 모듈을 사용하여 합성 데이터및 인간-표지 된 데이터를 사용한 스코어링 모듈.
지상 진실 레이블은 비슷한 작업에서 최소 31 시간 동안 훈련 된 5 명의 법률 전문가가 만들었습니다. 이 인간 전문가들은 216 개의 테스트 사례에 대한 종속성과 라이센스 용어를 수동으로 식별 한 다음 토론을 통해 결과를 집계하고 개선했습니다.
훈련 된 인간-보정 된자가 준수 시스템을 테스트하면서 chatgpt-4o 그리고 당황 프로, 특히 더 많은 의존성이 라이센스 용어 내에서 발견되었습니다.

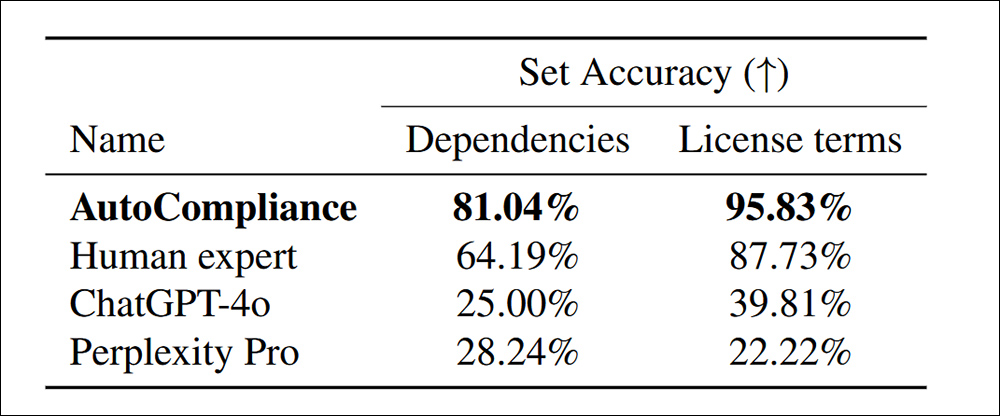
216 평가 데이터 세트의 종속성 및 라이센스 용어를 식별하는 정확도.
논문은 다음과 같습니다.
‘자동 준수는 다른 모든 에이전트와 인간 전문가를 훨씬 능가하여 각 작업에서 81.04% 및 95.83%의 정확도를 달성합니다. 대조적으로, ChatGPT-4O 및 Perplexity Pro는 각각 소스 및 라이센스 작업에 대해 상대적으로 낮은 정확도를 보여줍니다.
“이러한 결과는자가 준수의 우수한 성능을 강조하여 두 작업을 놀라운 정확도로 처리하는 데있어 효능을 보여 주며 AI 기반 모델과 이러한 도메인의 인간 전문가 간의 실질적인 성능 차이를 나타냅니다. ‘
효율성 측면에서, 자동 준수 접근법은 동일한 작업에 대한 동등한 인간 평가를 위해 2,418 초와 달리 53.1 초 밖에 걸리지 않았습니다.
또한, 평가 실행 비용은 인간 전문가의 경우 $ 207 USD와 비교하여 $ 0.29 USD입니다. 그러나 이는 매월 $ 14,225의 요금으로 GCP A2-Megagpu-16GPU 노드를 임대하는 것을 기반으로합니다. 이러한 종류의 비용 효율성은 주로 대규모 운영과 관련이 있음을 나타냅니다.
데이터 세트 조사
분석을 위해 연구원들은 3,612 개의 데이터 세트를 선택하여 Hugging Face에서 3,000 개의 가장 다운로드 된 데이터 세트를 2023 년의 612 개의 데이터 세트와 결합했습니다. 데이터 출처 이니셔티브.
논문은 다음과 같습니다.
‘3,612 개의 대상 엔터티에서 시작하여 총 17,429 개의 고유 한 엔티티를 식별했는데, 여기서 13,817 개 엔티티가 대상 엔터티의 직접 또는 간접 종속성으로 나타났습니다.
‘경험적 분석을 위해, 우리는 엔티티에 종속성이없고 의존성이 하나 이상인 경우에 종속성과 다중 계층 구조가없는 경우 엔티티와 라이센스 종속성 그래프를 단일 층 구조를 가질 것으로 간주합니다.
‘3,612 개의 목표 데이터 세트 중 2,086 명 (57.8%)은 다층 구조를 가지고 있었지만 다른 1,526 (42.2%)은 의존성이없는 단일 층 구조를 가졌다.’
저작권이있는 데이터 세트는 라이센스, 저작권법 예외 또는 계약 약관에서 나올 수있는 법적 권한으로 만 재분배 될 수 있습니다. 무단 재분배는 저작권 침해 또는 계약 위반을 포함한 법적 결과로 이어질 수 있습니다. 따라서 비준수에 대한 명확한 식별이 필수적입니다.

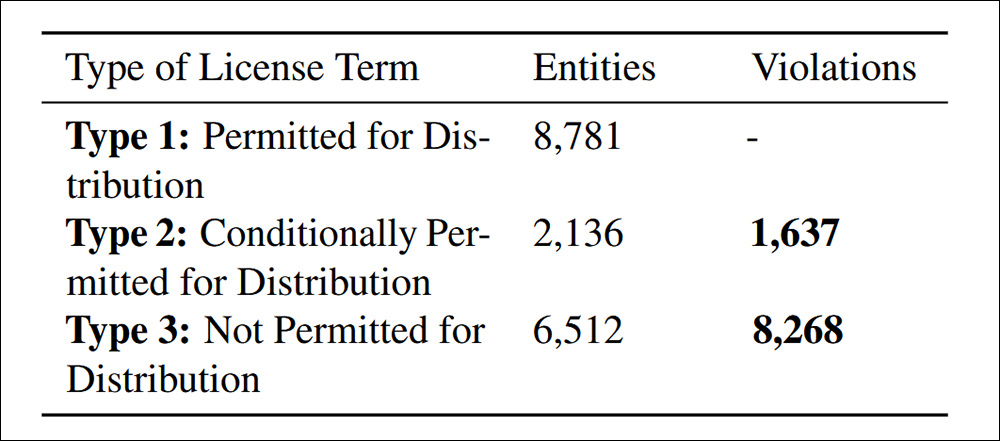
논문의 인용 기준 4.4에서 발견 된 분포 위반. 데이터 규정 준수.
이 연구는 9,905 건의 비준수 데이터 세트 재분배 사례가 두 가지 범주로 나뉘어져 있습니다. 83.5%는 라이센스 용어에 따라 명시 적으로 금지되어 재분배를 명확한 법적 위반으로 만들었습니다. 16.5%는 이론적으로 재분배가 허용되었지만 필요한 용어를 충족시키지 못한 경우 라이센스 조건이 상충되는 데이터 세트를 포함하여 다운 스트림 법적 위험을 초래했습니다.
저자는 Nexus에서 제안 된 위험 기준이 보편적이지 않으며 관할권 및 AI 응용 프로그램에 따라 다를 수 있으며, 향후 개선은 AI 중심 법적 검토를 개선하면서 글로벌 규정 변경에 적응하는 데 중점을 두어야한다는 것을 인정합니다.
결론
이것은 Prolix이자 대부분 비우호적 인 종이이지만, 현재 AI의 현재 업계 채택에서 가장 큰 지연 요소를 다루고 있습니다. 즉, 나중에 다양한 단체, 개인 및 조직에 의해 ‘개방 된’데이터가 주장 될 가능성이 있습니다.
DMCA에 따라 위반은 법적으로 큰 벌금을 부과 할 수 있습니다. 당사자 기초. 연구자들이 발견 한 경우와 같이 위반이 수백만 건으로 발생할 수있는 경우 잠재적 인 법적 책임은 정말 중요합니다.
또한 업스트림 데이터로부터 혜택을받은 것으로 입증 될 수있는 회사는 (평소와 같이) 적어도 영향력있는 미국 시장에서 무지를 변명으로 주장합니다. 그들은 현재 오픈 소스 데이터 세트 라이센스 계약에 묻힌 미로 시사점을 관통 할 수있는 현실적인 도구도 가지고 있지 않습니다.
Nexus와 같은 시스템을 공식화하는 데있어 문제는 미국 내에서 국가별로 또는 EU 내부의 최신 기준으로 교정하기에 충분히 도전적이라는 것입니다. 진정한 글로벌 프레임 워크 ( ‘데이터 세트 출처를위한 인터폴’)를 만들기위한 전망은 상충되는 동기에 의해서만 훼손됩니다. 관련된 다양한 정부 중 이와 관련 하여이 정부와 현재 법의 상태가 끊임없이 변화하고 있다는 사실.
* 저자의 인용으로 하이퍼 링크를 대체합니다.
† 논문에 6 가지 유형이 처방되지만 마지막 2 개는 정의되지 않았습니다.
2025 년 3 월 7 일 금요일에 처음 출판되었습니다
게시물 교육 데이터 세트의 거의 80%가 Enterprise AI의 법적 위험이 될 수 있습니다. 먼저 나타났습니다 Unite.ai.